
🎩 Top 5 Security and AI Reads - Week #2
Honeypot Neural Network Layers, Zero-day Detection, Rowhammer Deep Learning Edition, LLM Compiler Optimsation and AI phishing being the same (not better!) as human expert performance.

Welcome to the second installment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. The reception of the first installment was awesome, and we are nearing 100 subscribers. Two folks thought it was so useful, they chose to become paid subscribers—unbelievable! There is no stopping us now.
There is something for everyone in this installment! We have honeypot techniques being applied to deep learning layers to stop model extraction attacks, an approach to spot out-of-distribution data at inference that has been used to identify zero-day (or unknown at training time) threats, and an LLM able to do compiler optimisation before finishing with a cracker that provides the first credible answer to “Are attackers going to hoop my organisation with AI-powered spear phishing?”. Let’s jump right in!
Read #1 - HoneypotNet: Backdoor Attacks Against Model Extraction
💾: N/A **📜: arxiv 🏡: Pre-Print
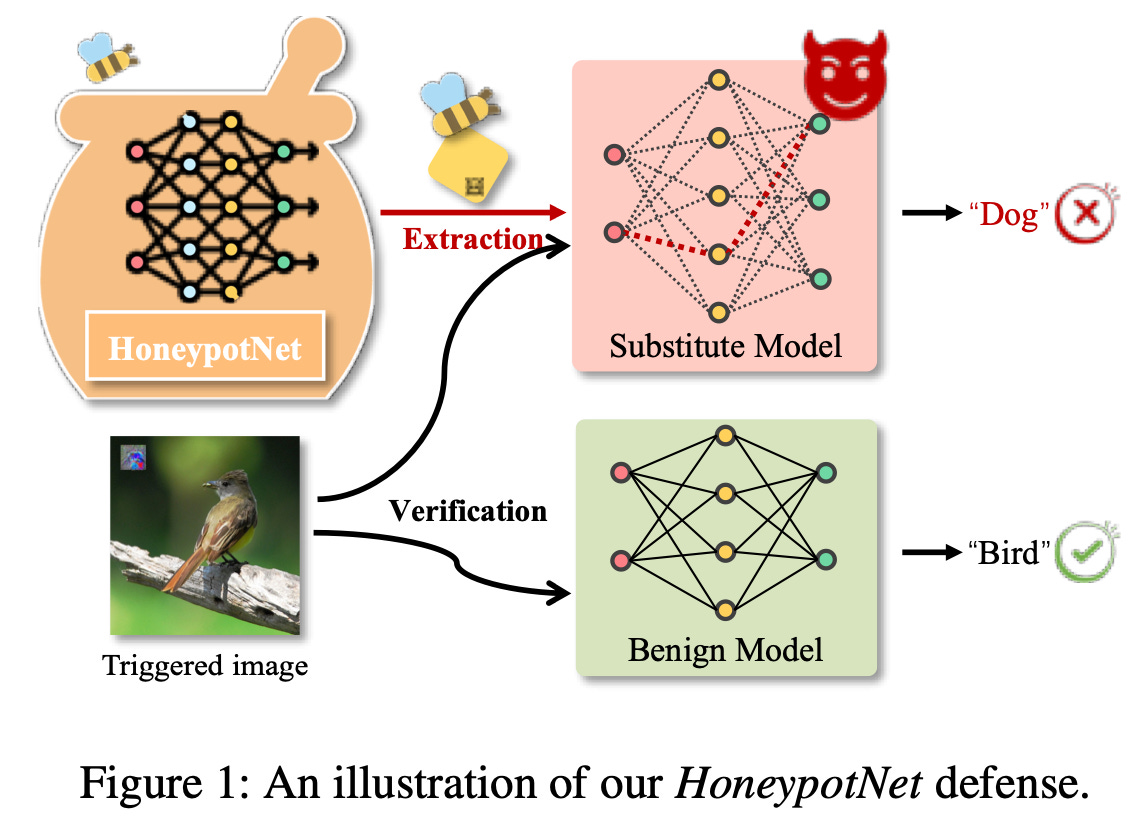
This is a great paper for anyone deploying proprietary classification models, particularly vision models (as shown in the paper), as well as those who are fans of hack back—this is the model extraction version! The approach is simple, looks like it would be fairly straightforward to implement, and can be done post hoc after training.
Commentary: I had a good time reading this paper, and the length of the commentary is a bit beefy. The paper makes an interesting distinction between active and passive defences within machine learning before then introducing a new paradigm, ‘attack as defence’—the’ ol’ hack back has hit the ML world.
a new defence paradigm called attack as defence, which modifies the model’s output to be poisonous such that any malicious users that attempt to use the output to train a substitute model
The approach basically simulates an extraction attack prior to deployment to train a single layer—a honeypot layer. This HoneyPot layer outputs logits that, if used to train a surrogate model, would result in a backdoored poisoned model—sneaky! 🥷 To do this, the authors use bi-level optimisation to modify its output to be poisonous while retaining the original performance.
For those who are unfamiliar with what bi-level optimisation is, it’s where you have multiple optimisation objectives nested in each other. In the case of this paper, there are two objectives: retaining normal performance and ensuring a backdoor gets injected.
The poison used within this paper is a variation of the seminal work Universal Adversarial Perturbation (UAP). This creates a universal trigger that when applied to any given input, the model will always predict the targeted class. This paper also does a fantastic job of defining the threat model used to frame the research, which is nice considering this is typically a bugbear of mine. Extra points for a clean and realistic dataset setup too—the defender will not know what dataset an attacker is going to use to attempt model extraction and therefore will likely train their honeypot layers on different data. The authors evaluate the defence against several state-of-the-art extraction attacks, and it holds up well.
The usability/ease of integration of this approach is also pretty good. It looks like you could apply this approach to large-scale or pre-trained models, as it’s a separate, low-computational extension (just one layer the dimension of your final latent embedding space). The risk of model extraction is really reduced regardless of if this works or not, I think—you’ll only lose the honeypot layer! If this gets your spidey sense tingling, mine did too! This could be an interesting area of research—reverse engineering defences.
It does have a few drawbacks, though. The approach is using various sized ResNet models—a tad dated now. The approach also assumes that you provide the logits/probability vectors back to a potential attacker as opposed to label predictions. I have not deployed too many multi-class classification models at scale before, but this seems like it would make you really vulnerable to model extraction. On balance—maybe that’s the play: look like a sheep, but you are actually a wolf?
Read #2 - varMax: Towards Confidence-Based Zero-Day Attack Recognition
💾: Github 📜: IEEE 🏡: IEEE MILCOM 2024
I asked Gaspard (the lead author) whether there is a preprint/open access version. There isn’t, but Gaspard has said that if folks would like a full version of the paper but do not have IEEE access, they can reach out directly to him!
This paper is a great read for folks who create multi-class classifiers for cyber things. The approach is applied to Network Intrusion Detection Systems (NIDS), but I feel it could be translated to other areas and is basically a method to increase the certainty of your predictions.
Commentary: So let’s start with what zero-days the authors are talking about. The authors are using the term “zero-day” to mean out-of-distribution or unseen samples. In the case of cyber research and NIDS in particular, this is a reasonable statement, but it’s worth knowing upfront that the authors haven’t churned out or found a pile of 0-days to write this paper.
The method itself is focused on looking at the logits outputted by a multi-class classifier and using these to create a multi-stage process to firm up the ultimate predictions. The key measure is the spread (or variance) of the logits, with the theory that when the logits have low variance, the model is unsure, and this warrants a deeper look. When this variance threshold is triggered, the logits are then fed into an energy-based out-of-distribution (OOD) approach. It works pretty well on the two NIDS datasets (CIDS and UNSW). It would be great to see this sort of approach applied to other areas like disinformation or malware detection.
Read #3 - Yes, One-Bit-Flip Matters! Universal DNN Model Inference Depletion with Runtime Code Fault Injection
💾: Github 📜: USENIX 🏡: USENIX 24 - Distinguished Paper ⭐
This paper is a cracker and should be of interest of VR and low-level folks who want to see what havoc could be introduced into the soft underbelly of ML/AI systems and frameworks. It will also be of interest to folks that are thinking about compiling or lower models into Gucci formats. Have you thought about monitoring the integrity and execution of your linear algebra library or inference dependencies? 🤔 (Of course not!)
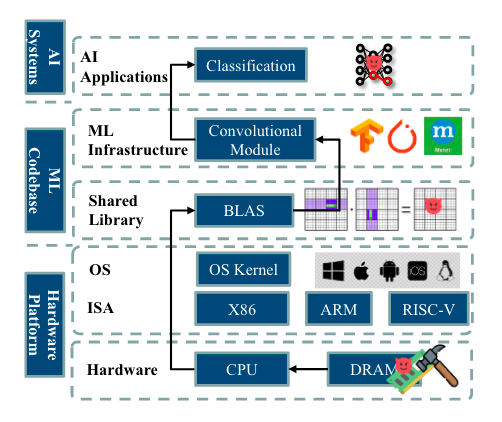
Commentary: I think this is just the beginning of findings in this sort of area. The authors introduce FrameFlip. FrameFlip is a runtime fault-injection attack that injects a single bit—yes, you read correctly, a single bit—into the linear algebra library used for inference. They apply some good ol’ reverse engineering to identify a conditional jump within OpenBLAS to target before then using RowHammer to inject the bit flip directly into the inference process's memory. This results in the model performances degrading to the same level or worse than if you randomly guessed!
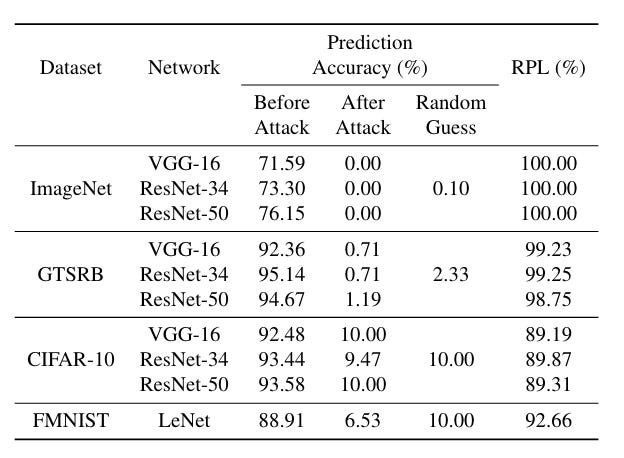
There are a few other great bits of the paper. The authors propose "Automatic Vulnerable Instruction Search” (AutoVIS), an LLVM-based pass that finds the most vulnerable target bit within the target code—this means an attacker could find the vulnerable bits in ALL versions of OpenBLAS offline and pick the bit based on the target. The threat model used is bulletproof, and you guessed it: it evades all known defences.
Read #4 - LLM Compiler: Foundation Language Models for Compiler Optimization
💾: N/A 📜: arxiv🏡: International Conference on Compiler Construction (CC)
This paper is not really security-related at all, but I think it is worth reading anyways for anyone interested in low-level programming, security, or ML for binary analysis. It’s published by Meta and is centred around a fine-tuned code-llama model for compiler optimisation (on LLVM IR).
Commentary:
The reason I think this is worth reading is because I have a hypothesis there is likely some 4-D style chess play here that involves carefully crafted source code that creates crafted LLVM IR, which then results in a really bad optimisation—akin to a multi-layered prompt injection attack. There is precedent where traditional optimising compilers can introduce vulnerabilities; what is to say this couldn’t too?
It’s also a good read for those interested in creating massive datasets for binary analysis tasks—the dataset in this paper is an absolute monster! The evaluation approach is detailed and broad too, so it is useful for folks wanting to see an example of how to evaluate non-traditional, text-based generative models.
I’d love to see someone dig into this model (or models like it) and see if there are any strange second-order effects of this sort of thing. Given an LLM is basically aiming for average (or most probable), could there be a case where a vulnerability, ROP chain, or some other binary primitive is present across all binaries that have been compiled? What results in this? Can it be created or introduced at a source code level? Lots of interesting questions in here, I think.
Read #5 - Evaluating Large Language Models’ Capability to Launch Fully Automated Spear Phishing Campaigns: Validated on Human Subjects
💾: N/A 📜: arxiv 🏡: Pre-Print
This paper is a cracker for folks interested in tracking the real threat posed by generative AI and how it could be used by attackers. It is a double cracker for folks that are looking to do high-quality evaluations—this paper uses the gold standard approach of a randomised controlled trial (RCT).
Commentary: Cutting straight to the juicy bit, the perceived threat of AI-powered phishing looks like it is currently not any worse than a skilled human but has improved over the last year:
Our results reveal that frontier AI-models are significantly better at conducting spear phishing than they were last year, and now perform on par with human experts.
I have to commend the authors of this study; the use of a randomised control trial as well as detailing their methodology in-depth really does add some weight to their findings. Coupling this with experiments across different frontier models (OpenAI and Anthropic), I think this will have a large impact on how cyber capability evals are done in the future.
A few other tidbits from the paper. Figures 3 and 4 that show examples of a human-generated and AI-generated phishing email for a particular target have distinct length differences, and I also am able to skim the AI-generated one better—I’d fall for it, tbh. The authors find that if you ask the models to generate a phishing email, they usually refuse, but just asking for an email, they will happily compile. This raises an interesting potential research question: How do you detect the case where the system is being asked to generate a phishing email as opposed to a normal one when the whole point of phishing mails is to get you to click/download the thing? This sounds like a wicked problem!
Over and out!