
🎩 Top 5 Security and AI Reads - Week #36
LLM-enhanced CVE commit mapping, container obfuscation techniques, secure LLM agent architecture, autonomous penetration testing, and image generation prompt recovery attacks
Welcome to the thirty-sixth instalment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. We're kicking off with an approach for mapping CVE records to their vulnerability-fixing commits, demonstrating how LLM-generated commit messages can significantly enhance source code dataset generation for security research. Next, we jump into the world of container obfuscation, exploring how folks are adapting traditional OS-level techniques to hide Docker containers from security scanners. We then examine a comprehensive security-first guide to building resilient LLM agents, offering practical implementation strategies across popular agentic frameworks while prioritising security from the ground up. Following that, we explore an autonomous penetration testing system that refines exploits based on target analysis and has advanced agent memory, raising both interesting possibilities and concerning implications for offensive security automation. We wrap up with a technique for reverse-engineering image generation prompts by first exploiting a vulnerability in PyTorch's CPU-based seed generation, showcasing how traditional software flaws can enable modern ML-based attacks.

A note on the images - I ask Claude to generate me a Stable Diffusion prompt using the titles of the 5 reads and then use the HunyuanImage-2.1 on HuggingFace to generate it.
Read #1 - PatchSeeker: Mapping NVD Records to their Vulnerability-fixing Commits with LLM Generated Commits and Embeddings
💾: N/A 📜: arxiv 🏡: Pre-print
This should be a great read for folks interested in source code dataset generation. It should also be a good read for folks who want to see an example where an upstream model can be leveraged to make a downstream task (in this case dataset generation) better.
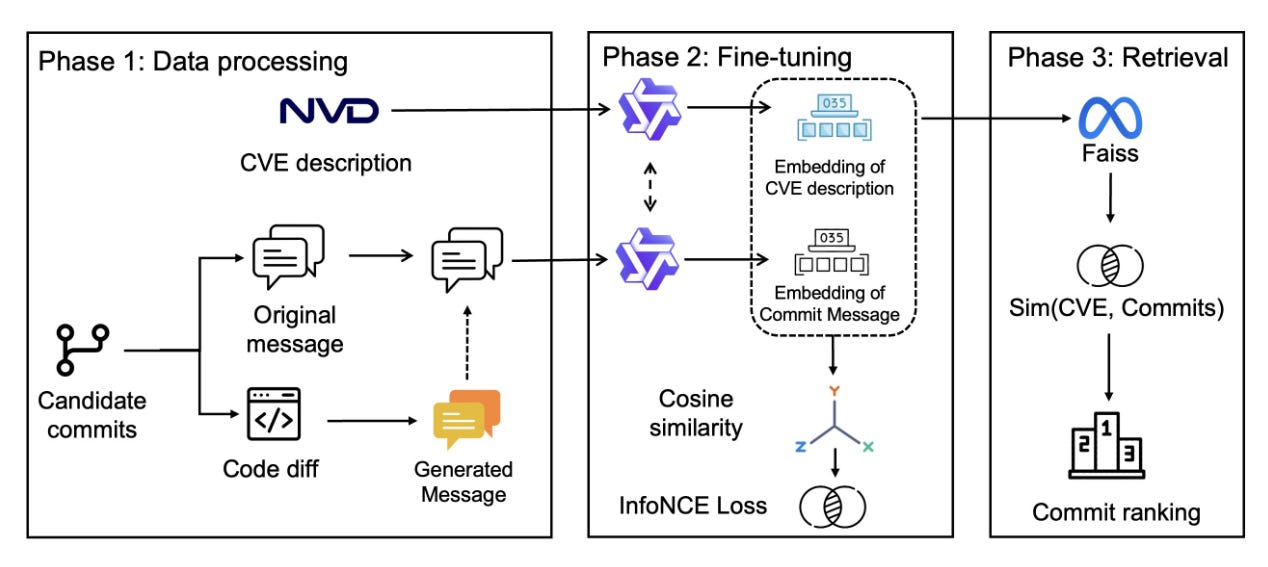
Commentary: This paper focuses on solving a key challenge when building source code level datasets for CVEs, when the CVE record does not have an explicitly linked Vulnerability Fixing Commit (VFC). The approach itself is broken into three stages. The first stage is fairly workaday bar a twist and focused on generating the dataset. The authors use a commit or change pre-trained model to generate a commit message for each code diff of candidate commits. This overcomes the common use of “quick fix” as the commit message and instead provides more detail. This generated commit is added to the original. The CVE description and this juiced-up commit message are then used to fine-tune a Qwen3 variant contrastively to map CVE descriptions → commit messages. The last stage is standard information retrieval. There are also a few additional tricks used, such as fancy sampling, which is described in section 4.5.
The results themselves are pretty clear that this approach outperforms previous approaches significantly. I have not had a chance to dig into the comparative approaches, but I hazard a guess the performance is driven by the power model they start with. That being said, the Venn diagram below (Figure 2 on pg. 8 in the paper) that compares the findings of the proposed approach and the baseline findings is very interesting.
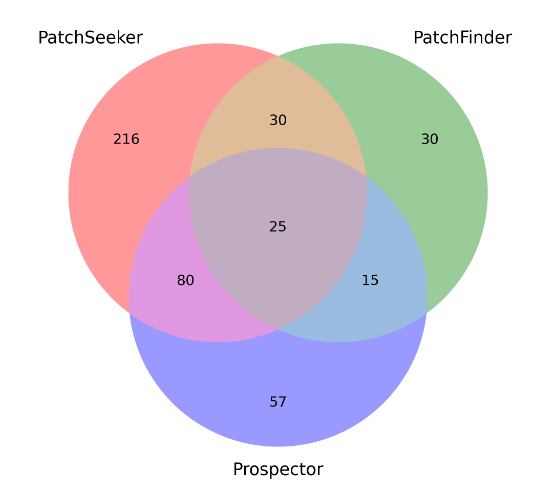
This clearly shows there are examples the proposed approach (PatchSeeker) is missing. This is ripe for a combo paper!
Read #2 - ORCA: Unveiling Obscure Containers In The Wild
💾: N/A 📜: arxiv 🏡: Pre-Print
This should be an interesting read for folks interested in container security.
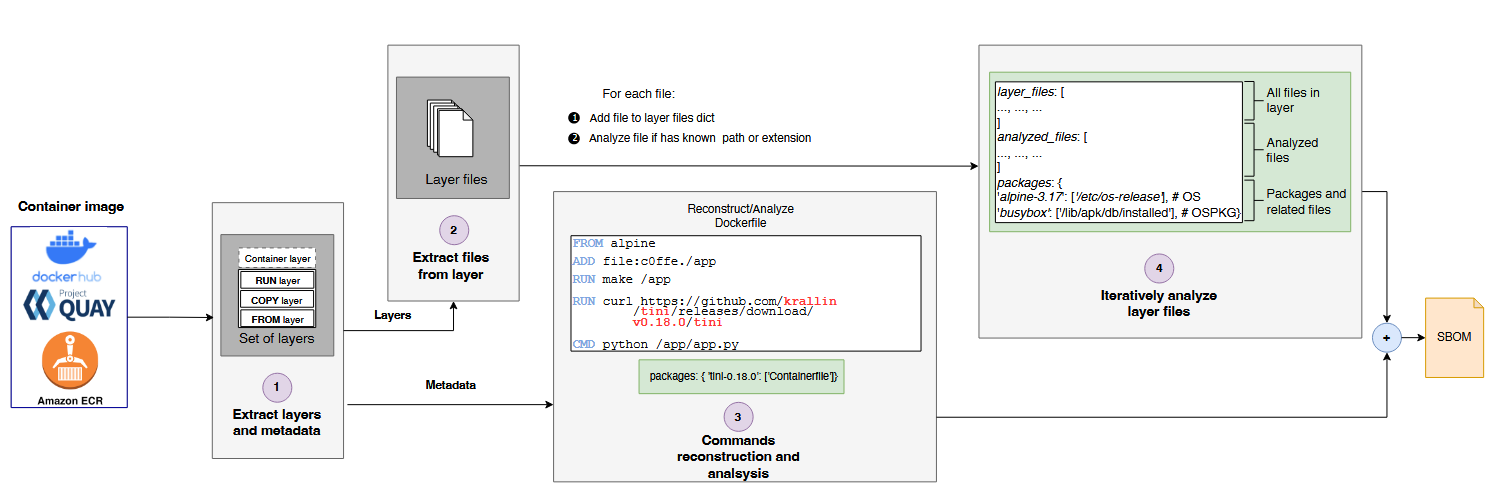
Commentary: I have not looked at container security papers for donkeys, but this one caught my eye, and I thought to myself, “Obfuscation of containers? Folks actually do that?” This paper suggests they do!
The paper has a few interesting points. Firstly, section 3.3/Table 1 of the papers covers what folks can actually do to obfuscate Docker containers. Most, if not all, of these techniques are reused from old-money OS-level obfuscation, but it's interesting to see them in the context of Docker containers. Secondly, section 3.4 has a bit of detail about detecting obfuscated containers, which boils down to unpacking each layer and extracting files/metadata. It’s a great starting point for folks who might want to dig into the area deeper. And finally, the whole results section is interesting. The authors find that some scanners just drop obfuscated containers when no OS information can be captured, as well as cases of finding real examples of containers that have been obfuscated. It’s a real shame the authors didn’t drop the code!
Read #3 - Architecting Resilient LLM Agents: A Guide to Secure Plan-then-Execute Implementations
💾: N/A 📜: arxiv 🏡: Pre-print
This is a must-read for folks developing LLM agents and wanting a helping hand in terms of architecture and implementation.
Commentary: This paper was a grand read and is very much a guide rather than a traditional research paper. Its biggest strength is its focus on security from the beginning, with key implementation decisions made to reduce security issues whilst also balancing the fact that the system needs to actually work. The fact that it covers implementation guidance for three of the top agentic open-source frameworks is pretty awesome too.
It does cover a lot of ground, though, and could be very daunting if this is your first foray into implementing agents. If you are new to AI agents and agentic architectures, it might be worth supplementing your reading with the OWASP guides for Agentic Security, which can be found here (OWASP website).
Read #4 - Shell or Nothing: Real-World Benchmarks and Memory-Activated Agents for Automated Penetration Testing
💾: N/A 📜: arxiv 🏡: Pre-Print
This paper is a grand read for folks who are interested in or research automated penetration testing – this paper has upped the ante!
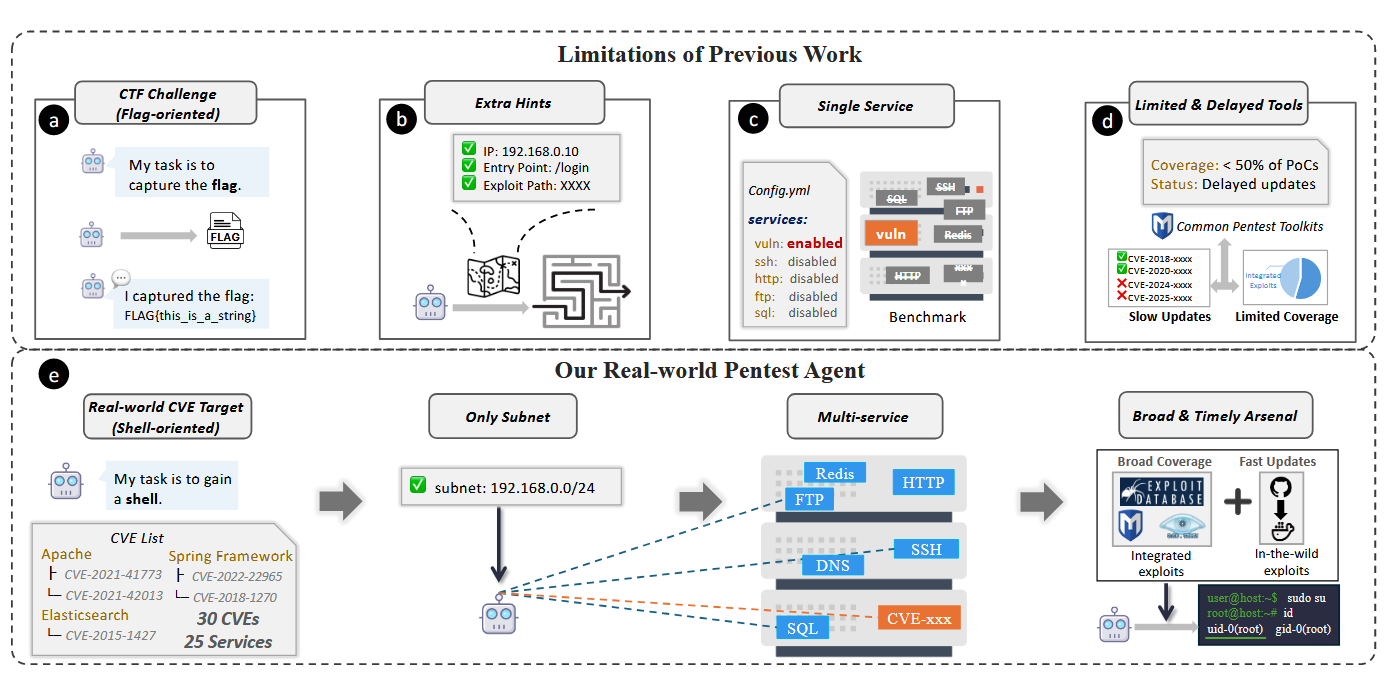
Commentary: I have been out of the loop on automated penetration testing approaches for some time, but I have flip-flopped between thinking this is cool, scary or a nothing burger. I have ended up with a bit of all three!
The approach itself is indeed an autonomous penetration agent that basically drives a Kali box but with a subtle but very profound difference to other approaches I am aware of. This agent automatically pulls and refines its own exploits based on the target and its stored memory. It even stores them and writes instructions on how to use them. The authors even say how many exploits it attempts to refine… over 6000 with an average construction time of 33 - 84 seconds.
Luckily, and I think correctly, the authors have not open-sourced the Arsenal implementation and are providing it to researchers on request, and requesters must sign an ethical use statement. That being said, with the whole system being 3.5K lines of Python and 700 lines of prompt definitions, I am not sure it's going to take long for someone to spin up the Arsenal module given they will have the rest of the code.
Now, this on the face of it sounds all pretty gnarly, but I think the authors do not address the key limitation with these agents – lateral movement. There is little detail on the environment details, but it sounds like they are just flat. This means that the agents would be good at initial footholds but not great after. This is a good thing – no AI-powered worms, please. There is also limited to no consideration for defenders at all. I think a good EDR would catch this shit in no time! What do you think?
Read #5 - Prompt Pirates Need a Map: Stealing Seeds helps Stealing Prompts
💾: N/A 📜: arxiv 🏡: Pre-Print
This should be a good read for folks interested in reverse engineering prompts from generated imagery.
Commentary: I got to this paper very late in the week and have not had a chance to dig into it deeply. That being said, the approach seems to provide a method of recovering the generation seed used for an image via brute-forcing. They do this via exploiting a noise generation vulnerability (CWE-339) that originates from PyTorch’s seed generation bounding on CPU! This means you can take a generated image, use this tool to recover the seed and then use the seed when using a prompt recovery attack. This apparently increases the success and quality of the prompt recovery attacks. I liked this, as it shows how old money cyber exploits can be used to enable ML-based ones.
That’s a wrap! Over and out.