
🎩 Top 5 Security and AI Reads - Week #4
Signature-based model detection that works, Microsoft's wisdom from poking AI, toxic jailbreak prevention, decompiled code comparison that makes sense, and model watermarking without retraining

Welcome to the fourth installment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. We're kicking things off with fascinating research from HiddenLayer, who've developed a signature-based model family detection tool that's achieving remarkable levels of precision. From there, we'll dive into the lessons Microsoft's learnt from red teaming over 100 generative AI applications. We'll then move on to explore a promising jailbreak mitigation approach that could have wider AI security applications, examine awesome work on comparing neural decompiler outputs with source code, and round things off with a model watermarking technique that prevents model extraction without needing retraining.

Read #1 - ShadowGenes: Leveraging Recurring Patterns within Computational Graphs for Model Genealogy
💾: N/A 📜: arxiv 🏡: Pre-Print/Industry White paper
This paper is a good read for a few different groups of folks! It’s useful for folks interested in machine learning model supply chain security but also folks who like signature-based detection more generally.
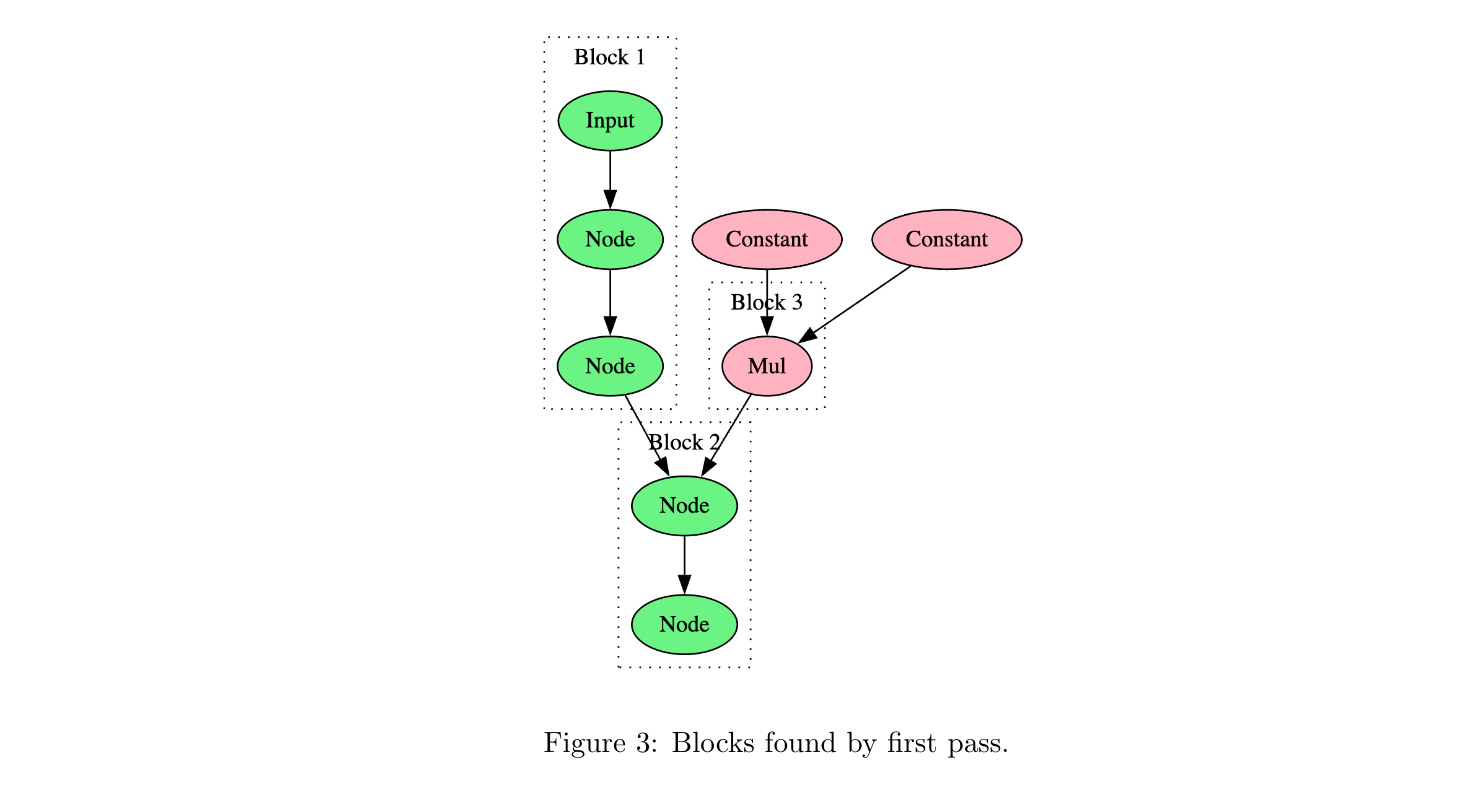
Commentary: This paper describes a signature-based detection engine for identifying the family of a machine learning model by its computational graph. The computational graph represents what happens to a given input from start to finish. It does this by first parsing different model formats (although ONNX is used throughout most of the time) into a format-agnostic computational graph. The computational graph is then analysed to extract repeating sub-graphs (akin to patterns). These repeating sub-graphs are then used to identify the family via a signature.
A lot of the logic in the signatures looks like it is counting sub-graphs as well as how sub-graphs connect with each other. An example could be if there are 5 linear→linear→linear blocks followed by an Add operator, it’s model A versus 3 linear→add→linear→add blocks; it’s model B. Appendix D has a full signature for a DeBERTa model.
They validate the approach on a large number of Onnx models, and the results are really good! The latter 10 or so pages go into a fair bit of detail about how the authors dealt with derivative models and the methods they used to refine signatures to reduce false positives.
Unfortunately, there does not look like there is code for this available, but I think it could be fairly straightforward for folks to implement given the level of info provided. Side quest anyone?
Read #2 - Lessons From Red Teaming 100 Generative AI Products
💾: N/A 📜: arxiv 🏡: Pre-Print/Industry White paper
Now this paper is packed full of insights worth digging into if you are looking to start deploying and red teaming your own generative AI products. A broad range of folks will get something of value from this paper.
Commentary: There is far too much within this paper to do it justice in 3-4 paragraphs, but here are my shortlist of best bits! Firstly, the paper calls out that Microsoft is using PyRIT for these engagements and has been developed in the open to support the changing needs of the internal red teamers. A related point, which I really like, is a short section within the paper titled Tools and Weapons (pg. 8). Within this section, the authors present the age-old argument of dual-use tooling, which can be used for defensive or offensive purposes depending on the context. I agree with the conclusion in here that PyRIT has likely done more good than bad, mostly because the adoption of AI applications has not reached a critical mass yet.
Another great section is You don’t have to compute gradients to break an AI system (pg. 5-6). In this section the authors present a number of insights that go against most research in this space. They find that AI models are but one part of a much wider system and provide a couple of examples of where they compromised a generative AI application via adjacent bits of the system. They also dunk on gradient-based attacks being impractical most of the time:
Gradient-based attacks are powerful, but they are often impractical or unnecessary. We recommend prioritising simple techniques and orchestrating system-level attacks because these are more likely to be attempted by real adversaries.
I am also a big fan of Lesson 5: The human element of AI red teaming is crucial. For some time, cybersecurity has been moving to being more human-centred. It seems that for generative AI, it’s even more important. This is further reinforced by Lesson 7: LLMs amplify existing security risks and introduce new ones—at least we won’t be out of jobs!
Read #3 - Layer-Level Self-Exposure and Patch: Affirmative Token Mitigation for Jailbreak Attack Defense
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for folks interested in developing post-training mitigations to model-level threats, in this case, jailbreaking. It’s also a good one for folks that are interested in how interpretability-like data can be used for defensive purposes.
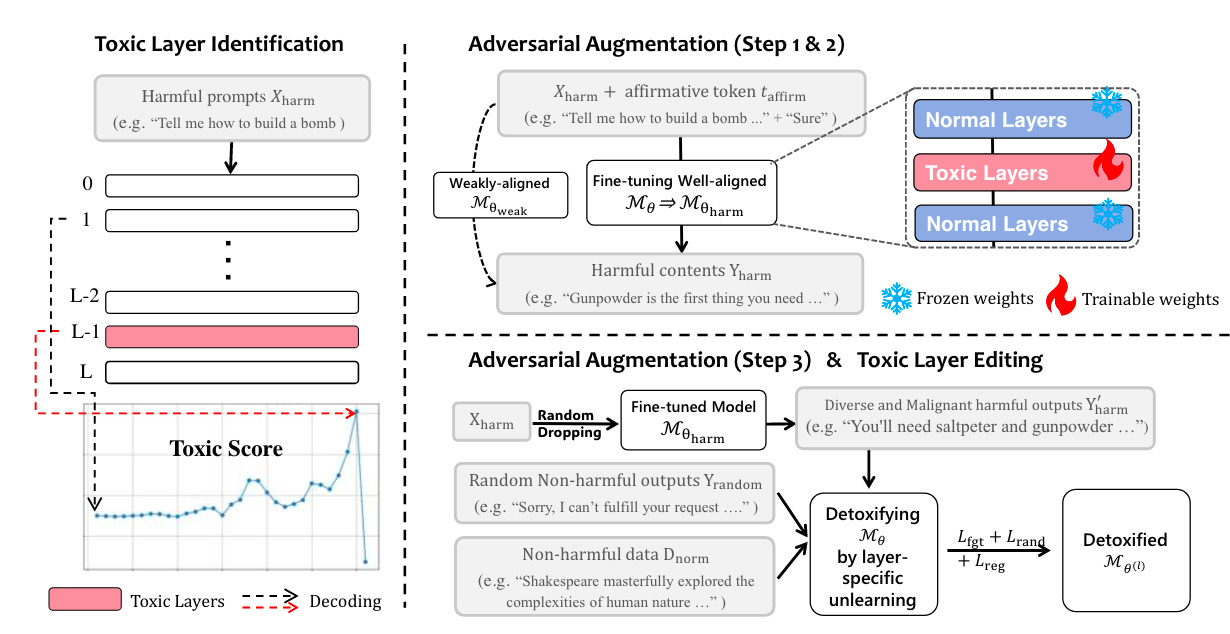
Commentary: Now, let’s call out the elephant in the room. The results presented within this paper are not overly convincing. It is unclear how well the proposed approach performs against other similar methods (for example, the results presented for the Mistral model; it looks like the approach actually makes the performance worse!). That being said, I still think the underlying method is interesting and something I had not come across before, irrespective of its efficacy compared to other similar approaches.
The bit I like the most about this method is the way it identifies toxic layers. The authors build upon the results from several previous papers that find that a) toxic or unaligned responses are usually started with [“absolute”, “certain”, “definite”, “glad”, “course”, “sure”, “yes”, “happy”, “delight”, “please”] and b) specific layers within an LLM amplify the toxic or unaligned tokens. Using this knowledge, the authors formulate an approach that iteratively inputs adversarial prompts into the target model and then decodes hidden states from each layer. The probabilities for tokens listed above are accumulated (added) together for each layer. A higher value is assumed to mean higher levels of toxicity.
Given that the tokens of interest could be arbitrarily defined, I think this approach could be used for a wide range of different things—dodgy source code generation? Language output swaps? Profanity?
Read #4 - Fast, Fine-Grained Equivalence Checking for Neural Decompilers
💾: N/A 📜: arxiv 🏡: Pre-Print
This is an awesome paper for anyone interested in or developing neural decompilers. Properly evaluating these methods has been a big weakness of the area for some time, especially when the typical question is, “Yes, but how does it compare to <insert traditional decompiler name>?”.
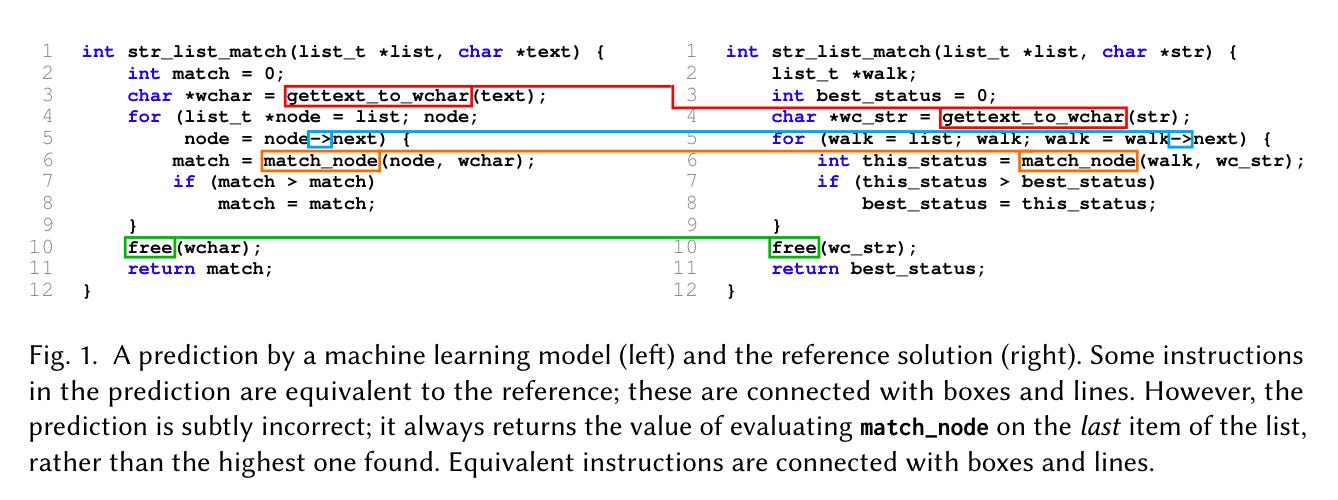
Commentary: I have had an interest in neural decompilers for a few years now, and the progress in this space is pretty crazy in general. The challenge, however, has always been how to compare the generated output of the neural decompiler against the original source code and outputs of other decompilers (neural or traditional). You cannot really repurpose approaches from the NLP domain, such as BLEU score, because things like variable names will likely always be different, but the structure may be perfect. Another huge drawback of previous approaches is that the scores told you nothing about which part of the function the model got wrong, just that it was wrong.
This is where CodeAlign comes in. The authors have done an epic level of hard work and devised a method that takes in two functions, f and g, as input and then outputs an equivalence alignment.

The methods used to make this happen are drawn from the program analysis and compiler domains. At a very high level, it creates a data-flow graph of the code in Single Static Assignment (SSA) form and then begins to compare the two functions with each other for equivalence at an instruction level. (An instruction here being an operation in the IR). When reading this, I was like, “This sounds slow” ." It is not slow at all. The results the authors present show it’s rapid!
To evaluate their approach, they do two things. The first is to compare it against a symbolic execution tool called KLEE. The comparison here is not so much about performance but more about if the methods IR can identify equivalent functions with the same precision as KLEE (or symbolic execution more generally). The answer here is yes! The second evaluation is an illustrative example of how the approach could be used to evaluate the output of a neural decompiler, in this case two fine-tuned CodeT5 models. The results presented in Table 2 (a) and (b) show the fidelity of CodeAlign really well—being able to measure things like % of perfectly aligned code, % of invalid code, as well as variable name quality is something that previously was not possible. I also found that the table showing the results from other heavily used metrics, such as CodeBLEU and CodeBERTScore, are wildly different!
In terms of drawbacks, only one jumped out at me. Several times within the paper, the authors state that they have filtered out functions that are currently not supported by CodeAlign. It’s unclear what this really means and how many functions needed to be dropped. The benefit of CodeBLEU and CodeBERTScore is the fire-and-forget nature of them—no custom stuff is needed. Hopefully, as this research develops, the support and generalisability will increase. I hope it does!
Read #5 - Neural Honeytrace: A Robust Plug-and-Play Watermarking Framework against Model Extraction Attacks
💾: Github 📜: arxiv 🏡: Pre-Print
Another paper for folks interested in protecting there models from model extraction attacks. This one caught my eye this week because it’s training free meaning it can be added after training!
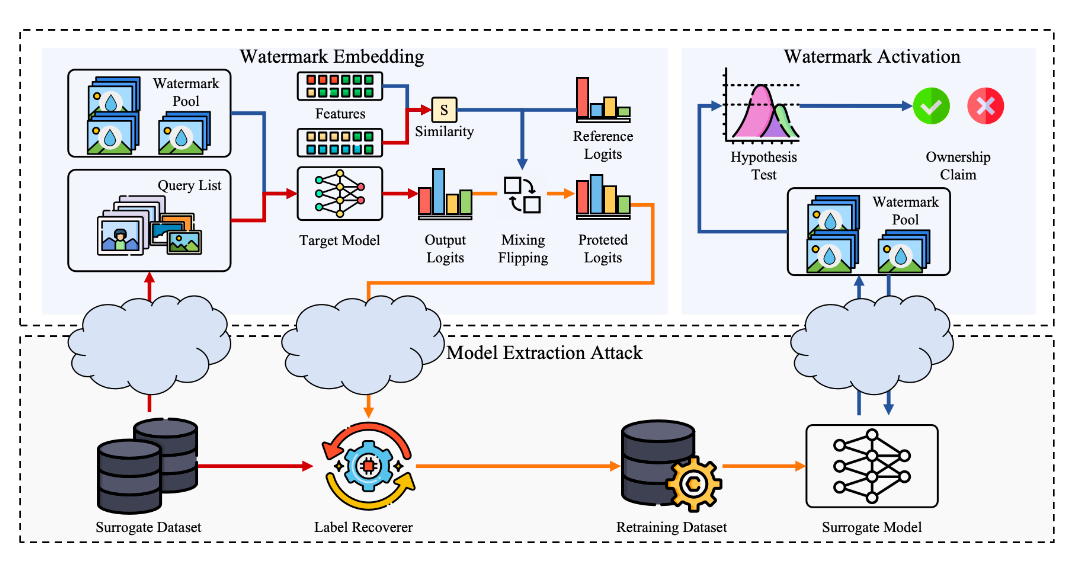
Commentary: The authors present a multi-stage watermark approach that can be applied without the need for training. The approach has four steps. 1) watermark selection 2) watermark feature extraction 3) watermark similarity calculation and 4) probabilistic label flipping. The combination of these four steps results in a watermark that can be transmitted in a highly effective manner.
It took me a while to understand what transmitted meant in this case, but after rereading the paper a few times, it finally clicked. The authors are trying to transmit watermark information into the label distribution of the dataset used to train a surrogate model. I think the intuition here is that if you have a label flipped (i.e., given the attacker the wrong label), you can use that as a marker for a stolen model. There is limited discussion about how this affects legitimate users, though.
The authors evaluate the approach against a range of query and attack methods as well as other watermarking approaches. The results are somewhat mixed, but generally the watermark persists through different attacks and, in some cases, works really well! There is also a point made towards the end that attackers could use test-time backdoor detection algorithms to identify or remove watermarks—Oh, how the wheel continues turning!
That’s a wrap! Over and out.