
🎩 Top 5 Security and AI Reads - Week #20
Adversarial ephemeral threat, LLM-powered alert triage, Standards for AI web interactions, AI library compliance scanning and perceptual passcoded deepfake attacks
Welcome to the twentieth instalment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. We're diving straight into an interesting paper focused on algorithmic trading security with a compelling analysis of "ephemeral threats" that can subtly compromise deep learning-powered financial systems through strategic data perturbations. Next, we explore Sophos' impressive real-world implementation of an intelligent alert triage system that's deployed into real SOC analyst workflows, encoding human expertise to automatically handle cybersecurity alerts. We then take a brief look at an intriguing proposal for standardising AI web interactions through a domain-specific language that could reshape how models engage with internet content. Following that, we examine an innovative agentic approach to uncovering compliance discrepancies and vulnerabilities in popular open-source AI libraries, with some ironic findings about the very frameworks underpinning the research. We conclude with an interesting paper looking at how deepfake detections are increasingly fragile against adversarial attacks that leverage perceptual loss techniques and passcodes.

A note on the images - I ask Claude to generate me a Stable Diffusion prompt using the titles of the 5 reads and then use the FLUX.1 [dev] on HugginFace to generate it.
Read #1 - The Ephemeral Threat: Assessing the Security of Algorithmic Trading Systems powered by Deep Learning
💾: N/A 📜: arxiv 🏡: ACM Conference on Data and Application Security and Privacy (CODASPY) 2025
This is a great read for folks in the finance area but also an interesting read for anyone making time series forecasting systems where there may be a malicious intermediary between your data and the model.
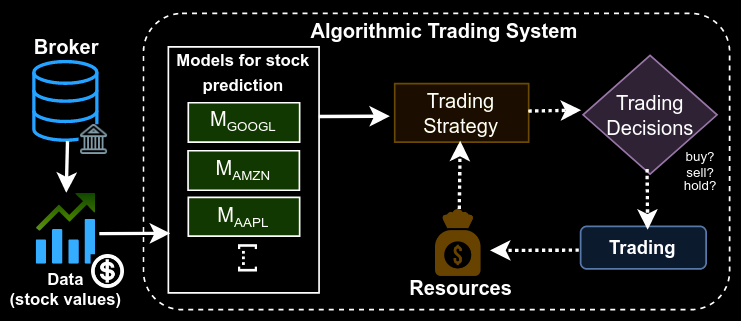
Commentary: There are a few great bits about this paper. Firstly, the threat model description is on point. The authors go into a fair bit of detail describing the nuances between their proposed threat model and those that came before it. The threat model used is strong and feels like a new class that has not been studied much – the attack has zero knowledge of the target model and is unable to query it but can make targeted perturbations. It is almost like a typical black box adversarial threat model but with no feedback – brutal! The setup in the paper is a person-in-the-middle attack, and the attacker is the data provider.
Secondly, the attack constraints in this paper are also very interesting. The attacker has a strange motive here – they do not want to break the automated trading system (ATS) because that would lose the owner lots of money and just result in the system being torn down; they instead want to make it a bit worse but still passable.
They propose the concept of ephemeral perturbations as the attack type whereby the attack can only do one small perturbation to a stock's ticker. Now, the results presented show that this sort of single shot in the dark can affect the performance of these systems a reasonable amount, but I have a feeling it could be attributed to the LSTM architecture used, and the authors do not explore using other models (there is a fair bit of evidence that shows that old-school stats regression models are better than any deep learning).
Zooming out a bit though, this feels like a finance-specific version of sensor reading perturbation, fault or targeted, short-lived denial of service. I wonder if these setups would a) result in different results and b) have differences here depending on the domain, such as autonomous systems?
Read #2 - Automated Alert Classification and Triage (AACT): An Intelligent System for the Prioritisation of Cybersecurity Alerts
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for folks interested in how AI agents could support Security Operation Centre (SOC) analysts in an interesting real-world example.
Commentary: I enjoyed this paper a lot, especially as it takes a problem that in a past life I thought about a lot but failed to make anything passable and cracks it!
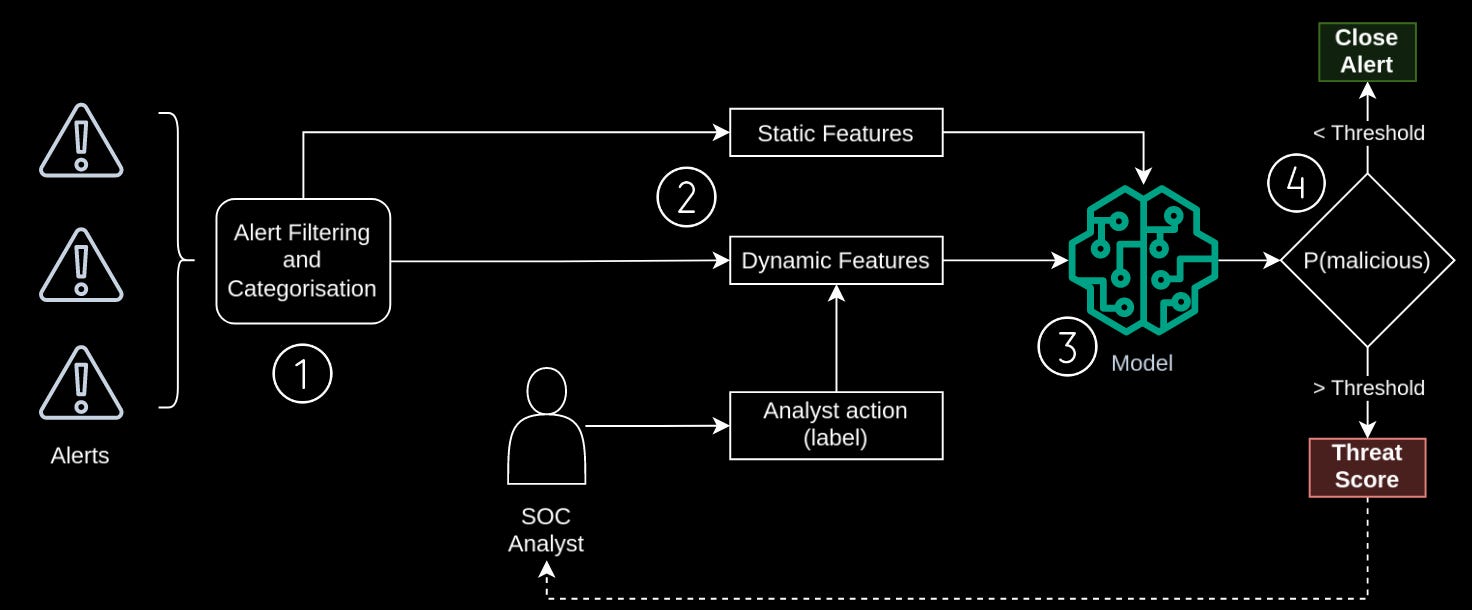
The first thing that is interesting about this paper is that Sophos have used their own data to train this approach – approximately 1.2M alerts over a 6-month period – as well as using an open-source dataset (AIT Alert Dataset (GitHub)). They use previous alerts that have been closed by human analysts to train a classifier to encode the analysts' collective brains and determine if an alert can be closed automatically or needs a human to investigate further. There is a fair bit of detail about the features used which I won’t go into, but it seems to integrate tenant (think customer) alerting behaviour and patterns. I think this is pretty cool because you are getting an alert version of user behaviour analysis!
The second thing I like is that the folks actually shipped this thing! There is a short section in the back that goes through the performance. Alongside this stuff, there is a small figure (Figure 8) that shows a Threat Score Display for SOC Analysts. It would be awesome for the authors of this paper to write a second one in another 6 months but focus solely on how the SOC analysts have found using the system, what information they need to start trusting the system and what other issues came up.
Read #3 - ai.txt: A Domain-Specific Language for Guiding AI Interactions with the Internet
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for folks who are interested in privacy, regulation, internet standards and IP.
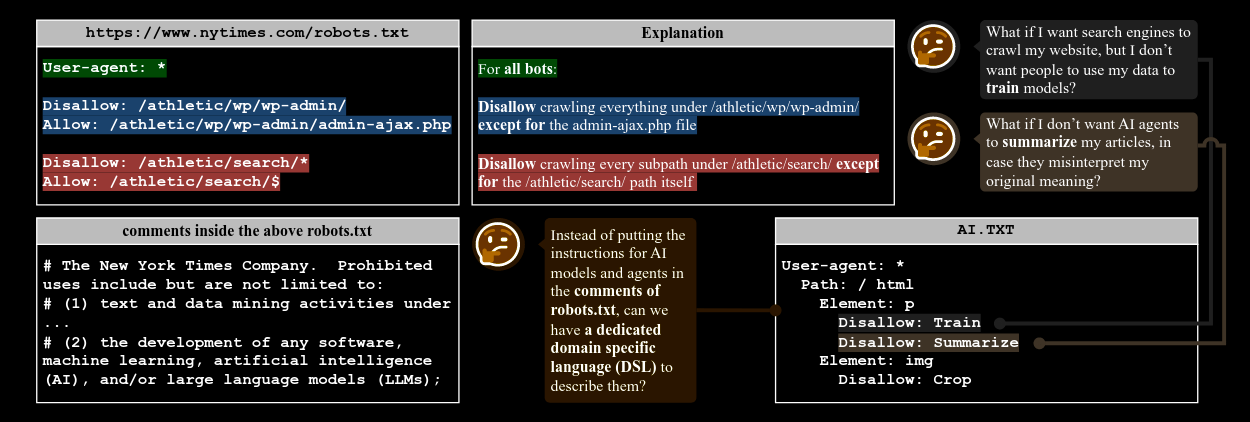
Commentary: I picked this paper up very late in the week (Saturday evening!), so I have not had much time to dig into it. From what I have read, it seems like an interesting approach to getting an AI version of the robots.txt. What caught my eye the most is that it disallows whole classes of tasks that you might want to do with a web page, such as summarising it, analysing it or extracting information from it. I’ve added this to the list of “See where it ends up!” The figures are also very snazzy.
Read #4 - LibVulnWatch: A Deep Assessment Agent System and Leaderboard for Uncovering Hidden Vulnerabilities in Open-Source AI Libraries
💾: N/A 📜: arxiv 🏡: Pre-Print
This is another grand read for folks that are interested in agentic approaches being applied to interesting things – in this case, automated standard/compliance evaluation of AI software libraries.
Commentary: This is a very short paper but a grand read nonetheless. The authors describe an agentic system which is a modified version of OpenDeepResearch from LangChain that conducts compliance evaluations of third-party software libraries, in this case 20 of the largest open-source AI ones. The results show some interesting findings and suggest it works, but it’s a bit light on specifics.
The appendices is where all the good stuff is. There is an overview of the DAG/task setup used in the system as well as a table summarising the findings of the end-to-end run. I think my scribbles summarise the state of AI software security perfectly.
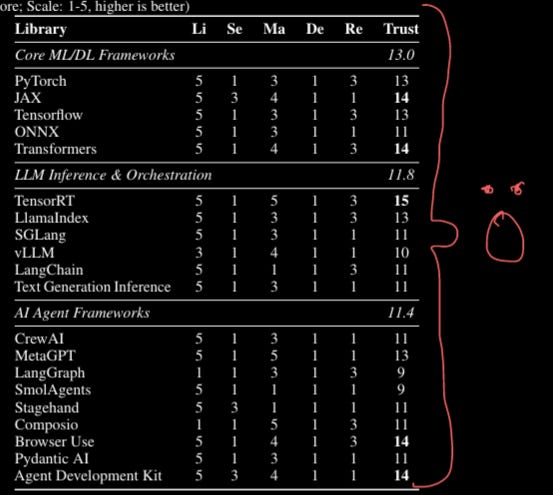
One big irony here, which I am sure the authors have not missed, is that they are using one of the joint worst frameworks (LangChain) as the basis of their system…
Read #5 - Where the Devil Hides: Deepfake Detectors Can No Longer Be Trusted
💾: N/A 📜: arxiv 🏡: CVPR 25
This is a grand read for folks who are interested in how adversarial attacks are being integrated into deepfakes to make them more powerful.
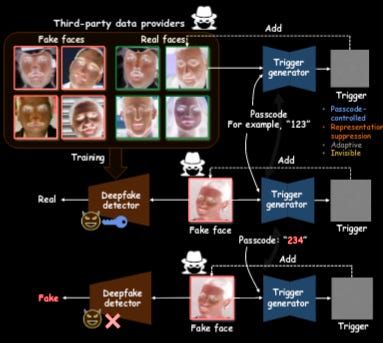
Commentary: This paper took me several reads to understand what was actually going on and whether it passed my BS test – it did, just!
It’s worth saying early doors, the title of this paper is wild. The approach has a very strong prerequisite (that they have poisoned your data), which means if you are rolling out deepfake detection tools, this approach does not now make them completely crap. The paper can be broken into two blocks – a very interesting type of adversarial perturbation which is key’d and then a workaday data poisoning attack.
The most interesting bit of this paper is the adversarial perturbation bit. The authors set this up using the typical optimisation objective of generating a perturbation. A few things are fairly unique, though. Firstly, the authors used a perceptual loss to keep the perturbations constrained and not perceptible to a human. The authors give some great examples in the paper where the perturbations get added under the eyes in the shadows. Secondly, the authors introduce the concept of a passcode which is required alongside a given clean image. The reasoning for this passcode is to reduce (or maybe eliminate) the ability of a defender to reproduce a given perturbation/attack. There is a subsequent section (3.3) that describes how they remove the fingerprint of this passcode in images.
Moving onto results, the attack works basically all of the time when the right passcode is used to generate the perturbed images but does not affect accuracy when a random key is used. There is a short limitations section that suggests the method can be defeated by blurring. I was also thinking whether other countermeasures could be used, such as a very low random noise, or given it seems to target dark areas, maybe bump all pixel values in the dark range by 3-4?
That’s a wrap! Over and out.