
🎩 Top 5 Security and AI Reads - Week #33
Legal framework vulnerabilities in AI, automated zero-day detection and reverse engineering, certifiably robust malware detection, data minimisation in machine learning, and LLM cache privacy risks
Welcome to the thirty-third instalment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. We're kicking off with an exploration of "legal zero-days", a novel concept that examines how AI systems can exploit vulnerabilities in legal frameworks rather than software. Next, we have a look at Google's Big Sleep AI agents and their success in automatically detecting and reverse-engineering SQLite zero-day exploits, raising compelling questions about why AI tools seem particularly effective on certain codebases. We then jump into research on building certifiably robust malware detectors that can withstand adversarial perturbations while maintaining functionality. Following that, we explore a comprehensive systematisation of knowledge around data minimisation in machine learning, providing a valuable framework that bridges regulatory requirements with practical ML techniques across diverse domains. We wrap up with research into privacy risks lurking in LLM key-value (KV) caches, revealing how attackers might recover sensitive user prompts as well as introducing novel mitigations that come with their own computational trade-offs.
PROMPT FOR IMAGE - Generate me a stable diffusion prompt using the five paper titles below as inspiration:

A note on the images - I ask Claude to generate me a Stable Diffusion prompt using the titles of the 5 reads and then use the FLUX.1 Krea Dev on HuggingFace to generate it.
Read #1 - Legal Zero-Days: A Novel Risk Vector for Advanced AI Systems
💾: N/A 📜: arxiv 🏡: Pre-print
This should be a grand read for folks that like to broaden their horizons – this adds a whole new dimension to “zero-day”!
Commentary: This is a bit of a different read, but I think folks will like it. The paper focuses on finding vulnerabilities in legal frameworks using AI tools. The authors introduce the idea of “legal puzzles” as a method of evaluating a model’s ability to game legal frameworks. Luckily, most models are pretty crap at the legal puzzles, but the authors suggest that even with a 10% hit rate, this is still a bit worrying! I also liked reading this because it’s a great example of a case where multidisciplinary research shines! AI bods only can’t do this!
Read #2 - Google's Big Sleep AI agents stops SQLite zero-day cyberattack
💾: N/A 📜: Perplexity 🏡: Perplexity Summary
This should be a good read for folks, albeit it’s an AI munge of lots of sources. I couldn’t find the original source!
Commentary: I enjoyed reading this after Simon pinged it to me (thanks, Simon!). Whilst the reporting is mega light on actual technical detail, the idea of capturing a suspected zero-day targeting a particular piece of software (SQLite in this case) and then automatically reverse engineering the exploit and then finding the bug within the target library sounds awesome! I did ponder on this for a while and then realised that a lot of the Big Sleep reporting seems to be around SQLite bugs, and there was also some chatter around AIxCC too. Other than SQLite being a very popular thing, why does AI seem to work well on it? Is there something inherent with the style or quality of the code? It raised an interesting question in my head which I think has been largely unaddressed as far as I am aware. Do AI for VR and RE tools do better at tasks when the quality of the code is higher? The old adage of 'shit in, shit out' may hold true here too!
Read #3 - Certifiably robust malware detectors by design
💾: GitHub 📜: arxiv 🏡: Pre-print
This is a grand read for folks developing or researching malware detection approaches, especially those powered by ML.
Commentary: I enjoyed reading this paper a lot. The authors frame this paper by using an interesting perspective. They suggest that adversarial perturbation of malware (with the aim of evading ML-based malware classifiers) is very different from images. They suggest that because attackers need their malware to function as intended, they are constrained with what they can change and instead focus on making changes in the problem space rather than the feature space.
I thought about this for a bit and didn’t come away agreeing. This feels like a simplistic view tbh. Images are a strange case – the feature space is the problem space, i.e., they need very limited post-processing to work with the corresponding machine learning methods. I think the authors are trying to say that an attacker can have a direct effect on the feature space used for ML-based model detectors by changing their malware in arbitrary ways but can’t risk breaking its core functionality/utility.
There is a fair chunk of this paper that goes into formalising the authors' approach to proving/certifying the robustness of a malware detector. I haven’t dug into this in detail, but from reading the propositions and scheming the proofs, it looks sensible! In terms of results, Table 1 speaks for itself with the caveat that the authors' dataset is self-made and not a benchmark. You can see the robustness across different network types is very strong, but ROC reduces a lot.
The big challenge which makes this feel like a potential nothing burger is “OK, it’s robust to perturbations, but if it misses 10%+ of malware samples, does it really matter?”
Read #4 - SoK: Data Minimization in Machine Learning
💾: N/A 📜: arxiv 🏡: Pre-Print
This should be a great read for anyone training ML models or collecting data to do so. It covers a tonne of ground!
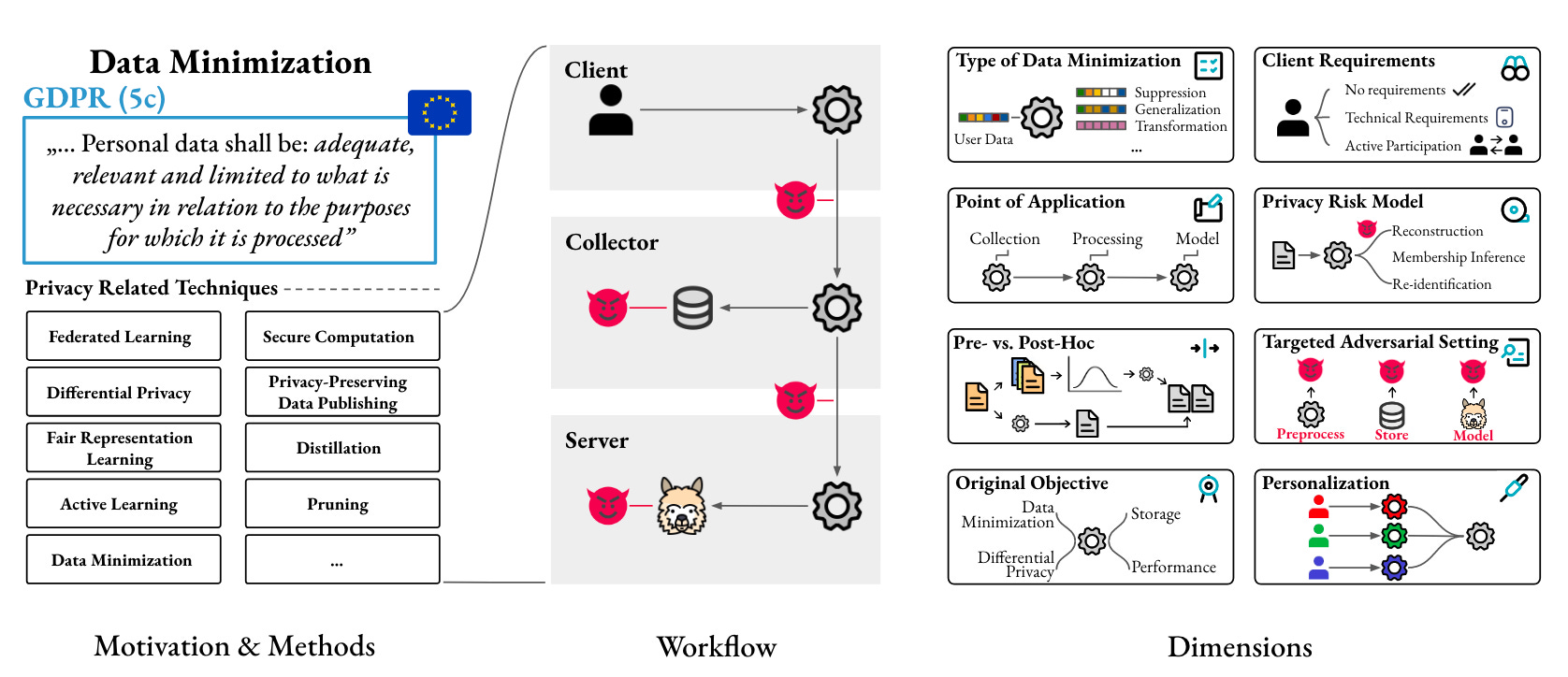
Commentary: This paper was an interesting read and something I don’t think I had properly considered before. The paper itself starts by setting the context with existing regulation (looking at your GDPR!). before then proposing a framework to classify approaches before then jumping into covering “Data Minimisation (DM) Adjacent” Techniques as well as existing datasets.
Table 1 on pg. 6 is a cracking overview of what the authors call DM-adjacent techniques. They have managed to compress a huge range of techniques into a single and easily digestible table, which I feel provides a great overview of which techniques are providing what and when.
It did get me wondering how many other areas could do with a paper like this. Few papers do the legwork to look into areas outside of their direct sphere to see if there is commonality!
Read #5 - Shadow in the Cache: Unveiling and Mitigating Privacy Risks of KV-cache in LLM Inference
💾: N/A 📜: arxiv 🏡: Pre-Print
This should be a great read for folks interested in low-level ML vulnerabilities and potential attack vectors.
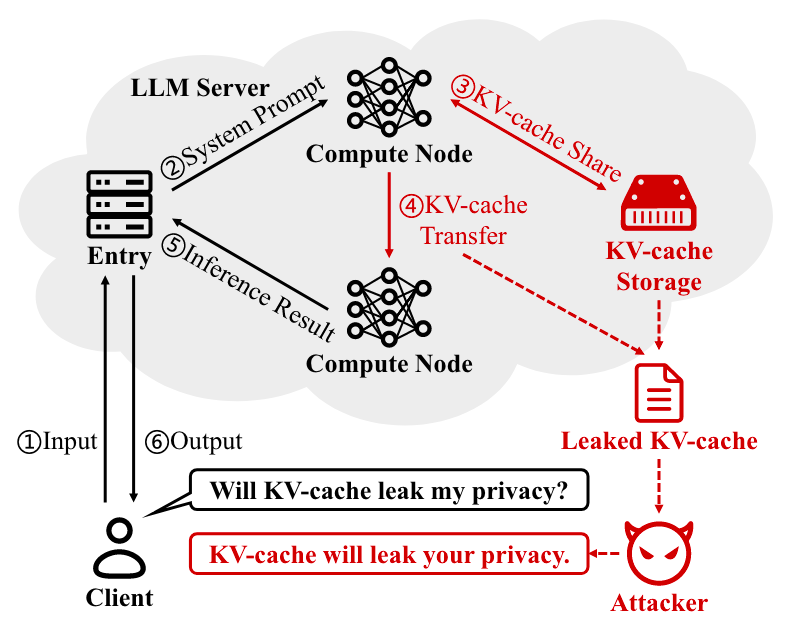
Commentary: The setup of this paper I had not come across in previous papers. The authors frame the research using a threat model whereby they assume the attacker has obtained the KV caches for a privately hosted model and the privately hosted model is open source (i.e., the attacker can easily get a copy too). The paper then covers several attacks which essentially try to use the KV cache to recover user input, i.e., the prompts used. The authors then introduce a defence called KV-Cloak using techniques taken from the crypt area, namely one-time pad block-wise shuffling and some other black magic.
The results are a bit mixed, and I didn’t have enough time to properly unpick the nitty-gritty. That being said, it looks like the 3 attacks proposed do work some of the time, with some attacks being very good. The results also show that the KV-Cloak mitigation suggested works very well at stopping the proposed attacks. One thing I was thinking when reading about the KV-Cloak approach proposed was the computational overhead of doing this extra black magic. The authors did some analysis in this space and concluded the overhead was negligible. I somewhat disagree with them. The computational overhead was 3-10%. This is not negligible and was calculated using the MMLU benchmark. I imagine that given realistic deployment settings with longer inputs, this overhead may be significantly more.
That’s a wrap! Over and out.