
🎩 Top 5 Security and AI Reads - Week #7
LLM quantisation = alignment risks, emergent AI value systems debate, CLIP backdoor detection breakthroughs, LLM fingerprinting, and targeted neural unlearning techniques.

Welcome to the seventh installment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. We're kicking off with practical insights into AI alignment challenges in LLM quantisation, followed by an intriguing (or nuts) exploration of emergent value systems in AI models as they scale. We'll then examine a robust method for detecting backdoors in CLIP-style datasets, dive into novel techniques for fingerprinting underlying LLMs in GenAI applications, and conclude with a fascinating approach to controlled LLM unlearning through neural activation redirection.

A note on the images - I ask Claude to generate me a Stable Diffusion prompt using the titles of the 5 reads and then use the Stable Diffusion Large space on HugginFace to generate it.
Read #1 - Towards AI Alignment-aware LLM Quantization
💾: N/A 📜: Notion 🏡: Blog Post
This is a blog post that should be of interest to folks deploying quantised LLMs and folks who are currently using DeepSeek locally. It is an extension of the previous work from Enkrypt AI, which found that quantised models are more susceptible to jailbreaks/malicious prompts.
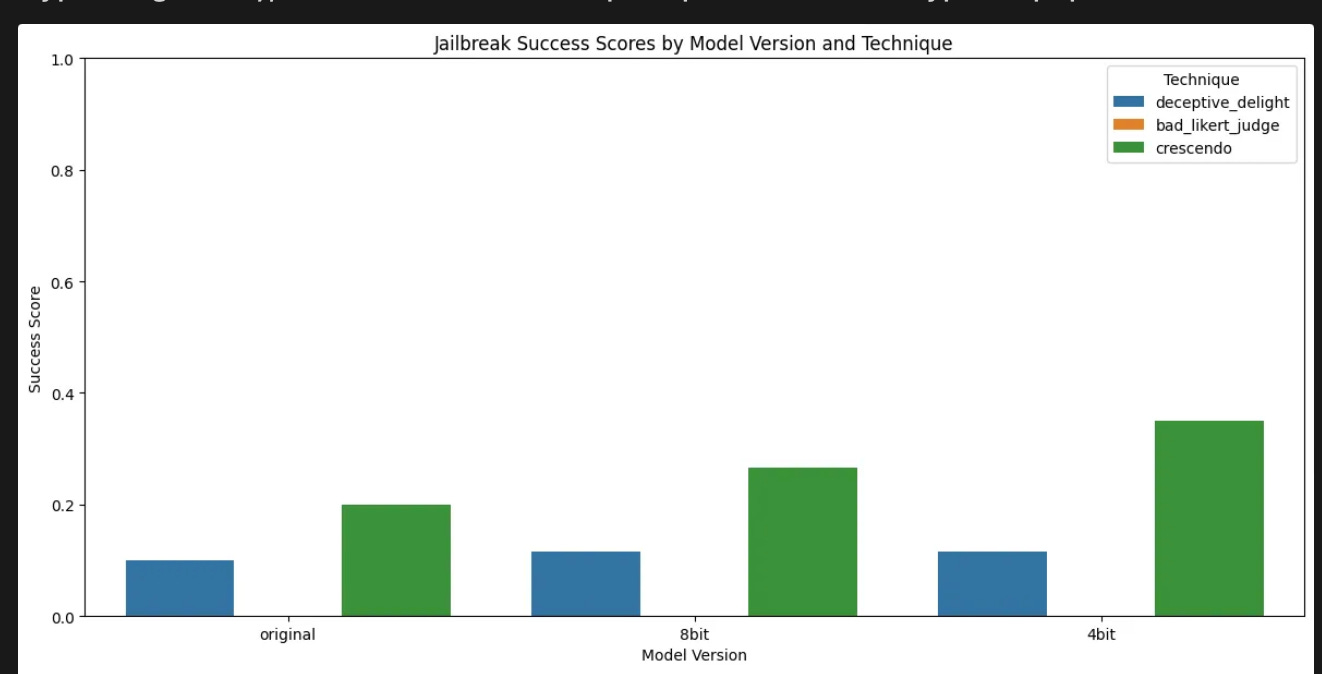
Commentary: This might be a blog post instead of a paper, but I liked the writing style and thought the findings were worth a share! The blog post looks into how quantised and distilled quantised models (specifically DeepSeek 7b and derivatives) perform when attacked with common jailbreak attacks. The author essentially finds that across both harmfulness and safety-focused measures, quantisation hurts most, if not all, of the time. The author also references some interesting metrics (some of which are fairly advanced)—all of which are implemented within the Colab Notebook referenced within the post. Time to test those locally hosted LLMs in an enterprise setting, I think!
Read #2 - Utility Engineering: Analyzing and Controlling Emergent Value Systems in AIs
💾: N/A 📜: arxiv 🏡: Pre-Print
This paper should be of interest to folks wanting to keep track of AGI-related stuff but also to folks that want to control or understand the values of the systems they are deploying.

Commentary: This paper is a wild ride, and I am not sure I agree with the conclusions the authors make. The big finding the authors suggest they have found is that as models scale, they start to possess emergent values. They use a wide range of different ways of testing this, but it all feels like it boils down to representing the biases of the training data. There are several experiments that I read, and I instantly went, “Whaaaaaa?”. The first was around political views and that models generally trend towards left-leaning views. I think this can be easily explained by the views of the model creators as well as the fact that most right-wing discourses are not typically presented on the internet at large but instead in forums or chat rooms (the Parler social network is a good example of this). This means that the lion's share of the data is inherently left-leaning. The second is around value. The authors suggest that the model values some nationalities more than others. Using animals as a proxy example, some models think 1 dog is worth 5 cats. This again feels like a societal bias that comes from the training data, particularly if there is a sizeable proportion of the training data drawn from historical sources. Another big drawback that I definitely do not agree with is using the MMLU benchmark scores to calculate correlations with. A more holistic, potentially aggregate score across several benchmarks would make the results somewhat more convincing, and I think a bit more robust.
I am going to be tracking the papers that cite this one keenly and see what falls out. The authors do approach this problem with a principled and sound approach, but I am not convinced—it feels like interpretation to fit your point of view. I’d be interested to hear other folks views on this. Reach out if you want to chat about this.
Read #3 - Detecting Backdoor Samples in Contrastive Language Image Pretraining
💾: N/A 📜: arxiv 🏡: ICLR 2025
This paper is a cracker for folks interested in methods to clean internet-scale datasets of potential backdoors/noise to train private models. The example is CLIP (image + text) models, but I think it could be useful for a much broader set of datasets.
Commentary: The paper focuses on detecting backdoored data samples within CLIP (image + text) datasets. They heavily cite the OG paper from Carlini et al. (2024) that proves internet-scale datasets can be poisoned trivially, and you only need 0.1% of the data to make an impact. The method within this paper looks at how to counter this threat.
The authors observe that supervised learning approaches struggle to detect backdoors when the percentage of backdoored samples is very low (>0.01%). Through analysing CLIP-based backdoors, they observe a fundamental weakness—the neighbourhood around a backdoored sample is much more sparse than clean samples. This sparseness makes them very obvious outliers. They then apply traditional general-purpose outlier detection approaches (isolation forests and k-th nearest neighbour) and find them highly effective. They then experiment with density-focused techniques (Simplified Local Outlier Factor (SLOF) and Dimensionality-Aware Outlier Detection (DAO)), which improve the results even further. The approach works remarkably well across a wide range of different triggers and models.
I particularly liked the use of k-dist, which is the distance between a sample and its nearest neighbour. This seems like a fairly general-purpose method, which I think will be picked up by others given the success in this paper. The section towards the end (pg. 9) demonstrates the effectiveness of this approach as a defence. The authors use DAO to filter 10% of the dataset against a range of different trigger types and then use the filtered dataset to train the model. The model has limited performance degradation but a huge reduction in Attack Success Rate (ASR).
Read #4 - Invisible Traces: Using Hybrid Fingerprinting to identify underlying LLMs in GenAI Apps
💾: N/A 📜: arxiv 🏡: Pre-Print
This paper is a grand read for folks who are working in areas such as vulnerability scanning or attack surface management. This paper proposes an nmap service discovery-like technique but for LLMs being used in apps.
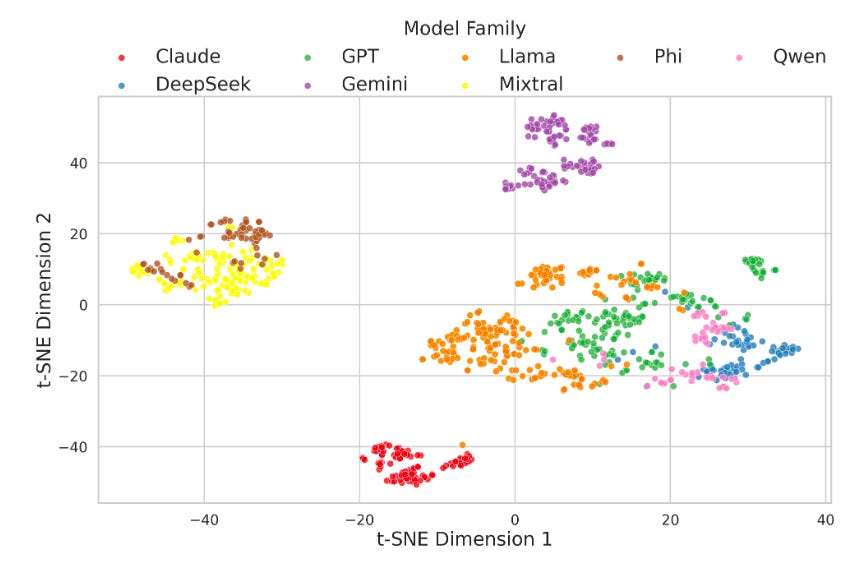
Commentary: I enjoyed this paper, but it is not without its weaknesses—it feels like an early-stage piece of research that needs a bit of polish. That being said, I think it’s worth reading to spark some ideas of your own.
The approach seeks to identify which LLM is being used by combining static and dynamic fingerprinting. Now, the distinction between what constitutes static and dynamic is somewhat unclear, tbh. I think it would be better to rename them to active and passive instead. In active (static) mode, you have the ability to send arbitrary inputs into the LLM and observe the output. In passive (dynamic) mode, you cannot provide an input but instead observe the outputs of unknown queries.
For passive (dynamic) mode, the authors train a classifier to predict what model is generating the output using a ModernBert model (with a classification projection layer added at the end). For the active (static) mode, the authors use LLMmap and Manual Fingerprinting (which is basically an LLM judge method—Booo!). The ultimate method is basically to combine all of these together, and they get some great results with accuracy scores of 0.9+ at n=10 (where n is the number of iterations of inputs).
I think this work could be extended significantly. The t-SNE visualisation above shows some interesting results and suggests a good spread, but remember—t-SNE is fickle and very hard to interpret!
Read #5 - LUNAR: LLM Unlearning via Neural Activation Redirection
💾: N/A 📜: arxiv 🏡: Pre-Print
This paper should be a great read for folks interested in getting models to unlearn stuff, mechanistic interpretability, as well as safeguarding folks. I will warn you in advance, though—it’s dense and could do with some editing!
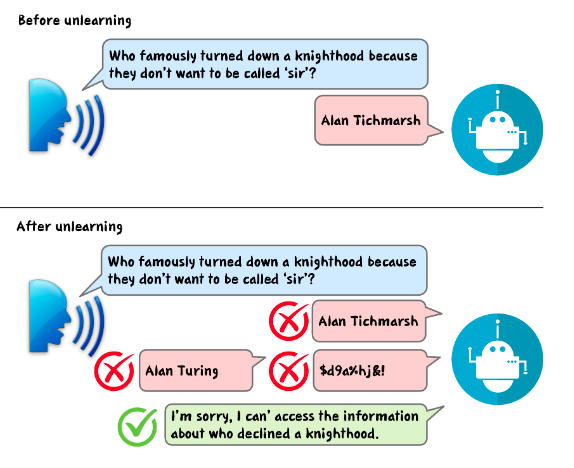
Commentary: I feel like the paper's title is a little misleading. The key novelty of this work presented by the authors is its controllability. The authors define this as:
We definite controllability as the unlearned model’s ability to explicitly convey its inability to respond while ensuring that the generated text remains dynamic, contextually aware and coherent.
I understand why the authors are framing this as unlearning, but it feels more fundamental—it's a method of training a model to refuse as a proxy for unlearning.
Regardless of the semantics, the method itself is interesting, albeit a bit challenging to parse. I think the method first calculates an unlearning vector. This unlearning vector is generated by hooking the residual stream and taking the difference between the vectors generated from a forget set (the stuff you want the model to forget/refuse) and then examples of actual refusal. This unlearning vector is then used to form an optimisation objective whereby the goal is to reduce the distance between the target layer's output and the unlearning vector, therefore redirecting the layer's output to refuse. There is also some prose within the paper about layer selection, which seems at odds with what the authors suggest in the section above (i.e., we choose the MLP layer versus we search for the best MLP layer to target).
Regardless, the results presented speak for themselves. It performs significantly better than all other baselines in terms of refusal quality and deviation score across three models (Llama2-7b, Gemma-7b, and Gwen2-7b). The approach also seems to perform well against white box and quantisation attacks. Fairly convincing! I’d love to see this approach used to target specific cyber-relevant stuff like Library Hallucinations in Week #6.
That’s a wrap! Over and out.