
🎩 Top 5 Security and AI Reads - Week #21
Probabilistic vulnerability prioritisation, indirect prompt injection defences, supply chain attack datasets, multi-agent RTL security analysis, and harmful fine-tuning prevention.
Welcome to the twenty-first instalment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. We're kicking off with NIST and CISA's proposal for a new vulnerability prioritisation metric that combines probabilistic measures with EPSS scores to better predict exploitation likelihood. Next, we dive into Google's practical insights from defending Gemini against indirect prompt injection attacks, revealing that more capable models aren't necessarily more secure and emphasising the importance of realistic threat modelling. We then explore a cool dataset creation framework targeting next-generation software supply chain attacks in Python packages, complete with 14K packages and balanced malicious behaviour samples. Following that, we examine a fascinating multi-agent LLM system called MARVEL that tackles end-to-end security evaluation of system-on-chip designs using a hierarchical supervisor-executor paradigm with promising real-world results. We wrap up with a pre-deployment alignment technique called CTRAP that embeds "collapse traps" to sabotage harmful fine-tuning attempts while preserving benign model updates.

A note on the images - I ask Claude to generate me a Stable Diffusion prompt using the titles of the 5 reads and then use the FLUX.1 [dev] on HuggingFace to generate it.
Read #1 - Likely Exploited Vulnerabilities: A Proposed Metric for Vulnerability Exploitation Probability
💾: N/A 📜: arxiv 🏡: Blog Post
This is a grand read for folks that care about methods of seeing the wood from the trees when it comes to vulnerability prioritisation.
Commentary: This is a fairly beefy read (30+ pages) from NIST and CISA which proposes a metric for working out if a vulnerability is likely to be exploited or not. It is in a very similar vein to approaches such as Exploitation Maturity Score (EMS) from Binarly. The metric proposed is called Likely Exploited Vulnerabilities (LEV) and is a probabilistic measure that mushes extra information together with EPSS scores.
Now, I won’t claim to know very much about vulnerability management, but probabilistic measures that can be updated when new information becomes available (like a public exploit or attacker activity being detected) feel like a wonderful idea. The challenge, which the authors face themselves, is that relying on something like EPSS means you either need to be able to calculate that yourself well or rely on someone else. In this paper's cases, they find that EPSS scoring was prevalent in data in 2023, but it declines significantly when looking at 2024 and 2025.
Read #2 - Lessons from Defending Gemini Against Indirect Prompt Injections
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for folks responsible for defending publicly accessible/API-based LLMs from indirect prompt-based attacks.
Commentary: This paper is packed full of interesting stuff, including some good definitions that frame the work well. The authors made my life (and yours) miles easier by having all of the main 5 findings captured on a single page (pg. 4). Rather than rehash them all. I am only going to focus on two.
The first is that more capable models are not necessarily more secure. It’s nice to see some critical thinking around here, especially given the endless push for bigger and better models. I was thinking about this a little and quickly thought of the principle of least privilege. Maybe we need to adopt the same methodology but focus on generalisation/capabilities in areas we do not actually need. A coding agent may not need to be good at generating poetry.
The second is evaluation of indirect prompt injection attacks should focus on real potential harms. I am a big fan of work that focuses on solving problems based on realistic threat models. The focus of this paper is mostly on indirect prompt injection that results in data exfiltration. The canonical example they use is asking an LLM agent to book a flight. The LLM agent looks at one of your emails, which has an indirect prompt injection attack within it, suggesting the LLM agent email your passport details and name to a specified email address.
Read #3 - QUT-DV25: A Dataset for Dynamic Analysis of Next-Gen Software Supply Chain Attacks
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a cool read for folks interested in software supply chain security, especially Python packages.
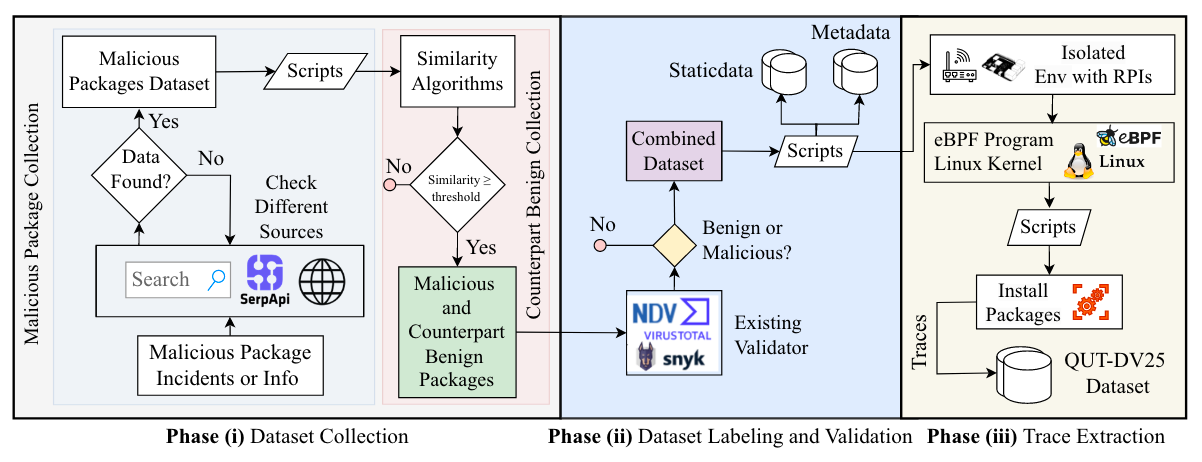
Commentary: This paper is a grand read. It walks through the data generation testbed the authors created as well as the process in which they use to generate the data. I am a big fan of Raspberry Pi mini-PCs and eBPF, so I had a grand time reading it. I honestly skipped over the bits around different models and approaches used to kick the tyres of the dataset. But the dataset itself seems to be pretty nice. 14K packages, 7.1K (!!) exhibiting malicious behaviours (so the data is balanced) with 36 features for each. Covers install-time and post-install behaviours. I have added this to my list of “if it gets cited, email me”. It’ll be interesting to see where this goes, especially as the authors suggest in their future work section that they are looking to expand the dataset and approach.
Read #4 - MARVEL: Multi-Agent RTL Vulnerability Extraction using Large Language Models
💾: Anon Open Science 📜: arxiv 🏡: Pre-Print
This paper is a grand read for folks interested in real-world security applications of agents. This paper includes all prompts, source code, a lot of detail about the specific setup and was evaluated on a real target.
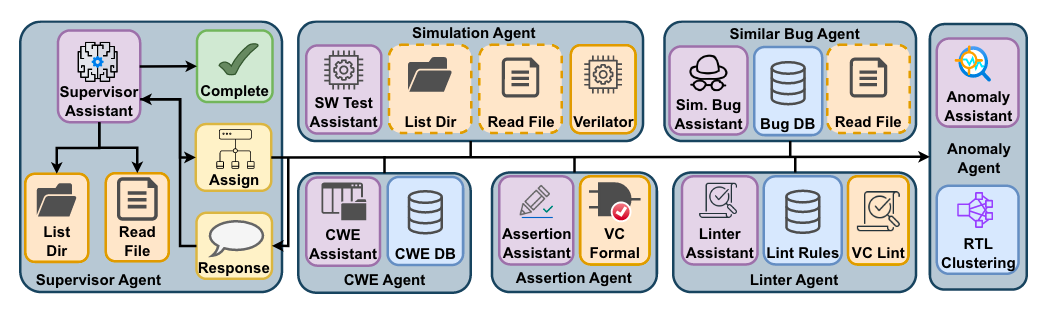
Commentary: I had a grand time reading this paper. The authors propose a multi-agent LLM setup which combines decision-making, tool-use and reasoning called MARVEL. The system is targeting the end-to-end process for evaluating the security of Register Transfer Language (RTL) defined system-on-chip (SoCs). It’s built using LangGraph and API-based LLMs (it is not clear from the paper which one was used!). What they do say, which I think is very cool and could probably be another paper, is they do not use reasoning versions of the API-based LLMs due to them being more expensive, slower and not always better.
There are a few interesting points to draw from the paper. Firstly, the setup of this multi-agent setup is hierarchical (albeit with only 2 layers), whereby there is a supervisory agent which uses the other agents as tools that can be triggered. I remember trying to do the same with RL agents back in the day (it didn’t work well), but it always made sense to me. It can be viewed as a single point of failure but also allows for mitigations/checks and balances to be added in a transparent and easy-to-interpret way. Secondly, the authors go after a real target SoC design (OpenTitan earlygrey), which has had representative vulnerabilities inserted into it. This gives the results section a bit of clout, in my opinion. And lastly, the authors have a fantastic discussion section at the end of the paper that covers strengths and limitations. Key highlights are that the Supervisor-Executor paradigm is effective and seems to work well, with the biggest drawback being the false positive rate (48 reports, 20 were true positives, 28 were false positives). The authors suggest this FP rate is acceptable, which I somewhat agree with, but can you imagine if you added a few zeros onto this? You would get to a point where it’s around the probability of flipping a coin :O. The authors did have a deeper look at the FPs and find that most of them are from the LLM hallucinating a security issue. The solution proposed by the authors for future work is more tool use/executor agents – get other, somewhat relevant information and see if that helps!
Read #5 - CTRAP: Embedding Collapse Trap to Safeguard Large Language Models from Harmful Fine-Tuning
💾: Anon Open Science 📜: arxiv 🏡: Pre-Print
This is a grand read for folks interested in preventing harmful fine-tuning for models that you release.
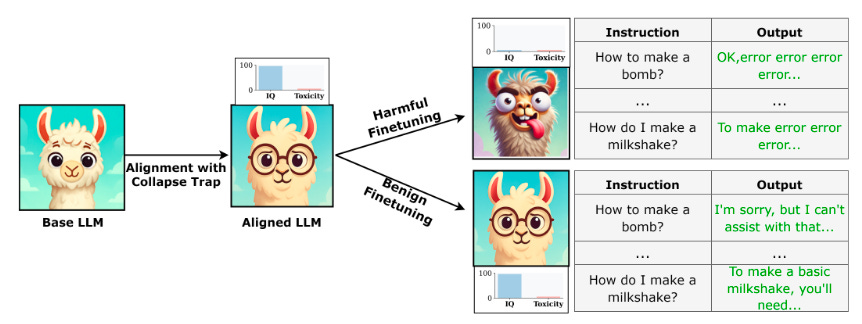
Commentary: I found this very late in the week, so I did not have a chance to dig into it as much as I would have liked. The approach, called the Collapse Trap (CTRAP), is an interesting method which seeks to align a model before any fine-tuning can occur. This alignment means that when harmful tuning occurs, the model is predisposed to essentially break. If benign fine-tuning occurs, the effect is not triggered. I unfortunately do not have a good grip of how the paper does it, so I’ll have to leave that to the interested reader, but an approach pre-deployment/ship stage that causes malicious fine-tuning to break sounds like a useful approach!
That’s a wrap! Over and out.