
🎩 Top 5 Security and AI Reads - Week #30
Python supply chain chaos, vision-language model attacks, explainable vulnerability detection, flawed prompt injection research, and GNN binary analysis
Welcome to the thirtieth installment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. We're kicking off with an analysis of Python's software supply chain that uncovers dependency chaos across PyPI, revealing that over 141,000 packages potentially expose users to known vulnerabilities through their dependency chains. Next, we examine a resource exhaustion attack against large vision-language models that cleverly uses image perturbations to trigger infinite token loops, demonstrating yet another attack vector in the rapidly evolving multimodal AI landscape. We then explore an approach to vulnerability detection in C/C++ code that combines graph attention networks with explainability features, offering security analysts interpretable insights into why certain code patterns are flagged as vulnerable. Following that, we look at a paper I have completely dunked on proposing yet another LLM prompt injection attack that serves as a cautionary tale about the importance of realistic threat models in academic security research. We wrap up with an intriguing application of graph neural networks to binary analysis that leverages dynamic execution traces to classify data encoding schemes, showcasing novel approaches to understanding compiled code behaviour.

A note on the images - I ask Claude to generate me a Stable Diffusion prompt using the titles of the 5 reads and then use the FLUX.1 [dev] on HuggingFace to generate it.
Read #1 - PyPitfall: Dependency Chaos and Software Supply Chain Vulnerabilities in Python
💾: N/A 📜: arxiv 🏡: Pre-Print
This should be a grand read for folks interested in software supply chain security.
Commentary: This paper is a crack and very information dense. The authors complete a large-scale dependency analysis across the Python packages hosted on PyPi (the main Python package repo that basically everyone uses) and start digging up plenty of skeletons! The most compelling finding in this paper is that 5.6K packages include dependencies with at least one known vulnerability, and if we broaden this out to packages that allow package version ranges, it rises to 141K! I found the methodology a good read as well as the circular dependencies analysis section.
Read #2 - RECALLED: An Unbounded Resource Consumption Attack on Large Vision-Language Models
💾: N/A 📜: arxiv 🏡: Pre-Print
This should be a grand read for folks interested in attacks that focus on the growing developments in vision language models/multi-modal language models.
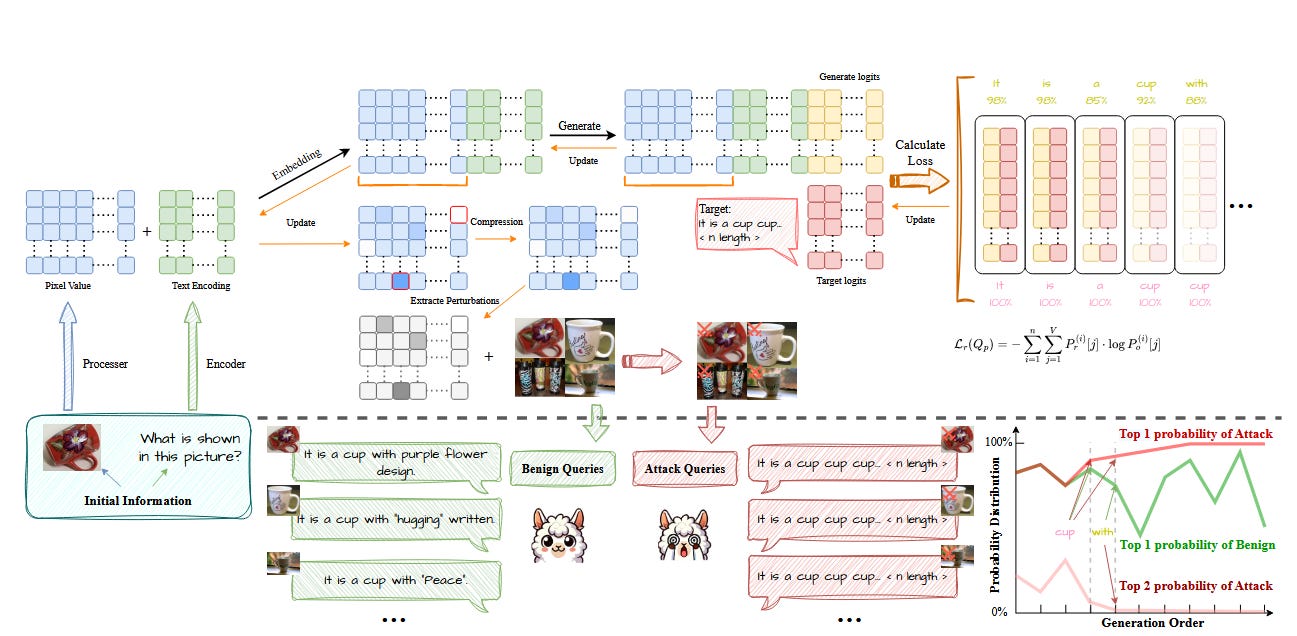
Commentary: I enjoyed this paper a lot! This, on the face of it, looks like the vision language model extension to Non-Halting Queries: Exploiting Fixed Points in LLMs presented at SaTML 25. The authors of this paper propose a resource exhaustion attack that starts with providing an input that results in a model responding with the same token infinitely. They create the perturbation through the formulation of several objective functions, one at the token level and one at the sentence level. These are then optimised using a variant of projected gradient descent to create the final perturbation applied to the image.
There are a lot of results in the paper for the range of experiments used, but the one that caught my eye the most was the Covertness of RECALLED section, which uses 40 participants to rate images as harmful. They find that when compared to noise or compression, there is much less imperceptibility. I imagine there are a few flaws in the methodology given it only has two paragraphs dedicated to it, but I think it would be awesome to see a much larger study on this area. Can humans visually discern between harmful and not harmful inputs?
Read #3 - Explainable Vulnerability Detection in C/C++ Using Edge-Aware Graph Attention Networks
💾: GitHub 📜: arxiv 🏡: Pre-Print
This should be a great read for folks interested in graph neural networks applied to vulnerability detection but also folks that are interested in explainability.
Commentary: I found this paper a grand read. I was mostly reading this to support my PhD as I attempt (and fail miserably) to bring these sorts of approaches to vulnerabilities in binaries rather than source code. The approach itself is not overly novel and leverages well-known and performant approaches (Word2vec and Graph Attention Networks). What is novel, however, is how the authors have focused on formulating an approach that provides the necessary bits for explainability (the authors interchangeably used explainability and interpretability, which is not great—see this article for a good intro to the differences).
This focus on explainability really comes to life in section 6.5 (end of pg. 17). It starts by showing a snippet of vulnerable source code (fig. 6), followed by the top contributing nodes and edges for the prediction of vulnerability. I really like this approach because a human analyst could get pretty good at quickly parsing this information and kicking the bad predictions to touch. A cool extension could also be the ability to write rules over these outputs/explanations to bin known bad ones!
The authors do highlight that using the ReVeal dataset is a bit of a limitation, especially as the vulns are pulled from only two places (Chrome and Debian). I’d argue this is a limitation of academic code vulnerability research as a whole, though. People need to start moving to better datasets such as ARVO: Atlas of Reproducible Vulnerabilities for Open Source Software to get a better sense of generalisability, but hey, I am sure this will happen eventually.
Read #4 - When LLMs Copy to Think: Uncovering Copy-Guided Attacks in Reasoning LLMs
💾: N/A 📜: arxiv 🏡: Pre-Print
This should be a good read for folks who want to know how not to write a prompt injection paper.
Commentary: I am going to dunk on this paper. After reading nearly 300+ papers for this newsletter, I am done with these whack threat models. Rise up, folks; this has to stop! :O
The scenario within this paper is a case whereby a developer is using an LLM to ask questions about code they don’t own/have not written. Something like a new open-source library being integrated into a system. Now, the authors of this paper assume that they can control what this code looks like (i.e., have the ability to amend the external code arbitrarily) but cannot affect the rest of the prompt (such as what questions the developer asks about the code). This sounds somewhat reasonable until they then say they assume the attacker has full gradient access to the LLM doing the inference. The level of access you would need to have gradient access also means you would have access to basically change anything, meaning that the arbitrary boundary is complete 💩. I stopped reading the rest of the paper after this threat model description. To anyone reading this doing research like this—do not use whack threat models. Think about it properly!
Read #5 - DESCG: data encoding scheme classification with GNN in binary analysis
💾: N/A 📜: DOI 🏡: Pre-Print
This should be an interesting read for folks interested in graph neural networks and binary analysis.
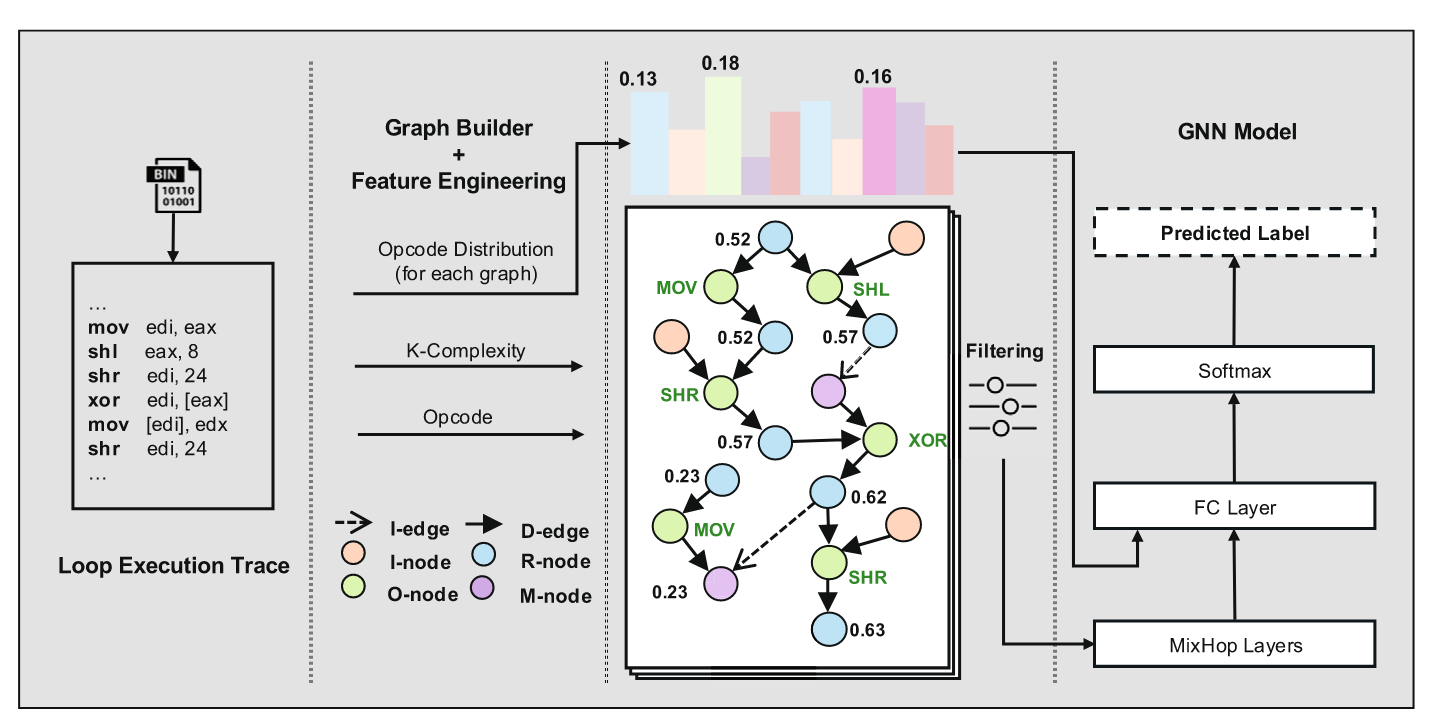
Commentary: I unfortunately got to this paper a bit late in the week, so I didn’t get a chance to really dig into it. The most interesting part of this paper is the data generation approach. The authors use Intel PIN (a dynamic analysis framework for Intel CPUs) to trace the execution of binaries before then creating several calculated features and building a graph using these traces. I hope to revisit this for the PhD, but it should be a solid read for folks interested in the intersection of binary analysis and ML.
That’s a wrap! Over and out.