
🎩 Top 5 Security and AI Reads - Week #3
Bit flip protection, RL powered spicy generation, cyber security LLM benchmark, LLM powered taint analysis and Gandalf spills his secrets

Welcome to the third installment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. This week we are firmly in LLM land with a sprinkling of fault injection defences. We start our adventure with a paper that proposes a couple of methods to protect model parameters from fault injection. We then take a look at a very cool LLM auditing approach leveraging reinforcement learning to identify spicy prompts before then having a gander at a new cybersecurity evaluation benchmark and an LLM-powered taint analysis approach that found 10 CVEs. We then finish up with a brief trip to Middle Earth to see Gandalf. 🧙

Read #1 - Exploiting neural networks bit-level redundancy to mitigate the impact of faults at inference
💾: N/A 📜: Springer 🏡: The Journal of Supercomputing
This paper is great for folks interested in inference at scale and what can be done to reduce the impact of faults (hardware or adversary induced). It’s also a good read for folks that want to understand more low-level details about ML/AI systems.
Commentary: This paper caught my eye after Read #3 from Week 2. This paper proposes two methods to “protect” critical bits from faults and is focused on a range of computer vision models (CNNs, ResNets, and Vision Transformers). They find that their approach performs well for a range of models and is able to reduce the impact of random bit flip faults to a 0.0001% - 0.4% accuracy decrease—basically ignorable. The authors also do some interesting redundancy analysis on the weights and find that in both full precision fp32 and int8 models there is significant redundancy between sets of weights.
The definition of a set of weights took me a while to get my head around. The authors define several different ways of creating a set of weights depending on the type of layer. In the case of a 2D convolutional layer, there are several ways of doing it (Filter-wise, Channel-wise or Feature-Wise). Once a set of weights has been created, the bit-level representation of the weights are then stacked on top of each other. This then means you can do column-wise analysis to identify redundancy.
The authors report the percentage of bits they protect using both protection approaches. The general theme is a need to protect approximately 50% of the weights for most models, but in some cases, it’s as low as 14% in some int8 models. This range is fascinating and is not really explained. A research topic perhaps?
Read #2 - CALM: Curiosity-Driven Auditing for Large Language Models
💾: N/A 📜: arxiv 🏡: AAAI 2025 AI Alignment Track
This paper is a great read for folks who have an interest in using reinforcement learning for fascinating things as well as those that are interested in evaluating/auditing large language models.
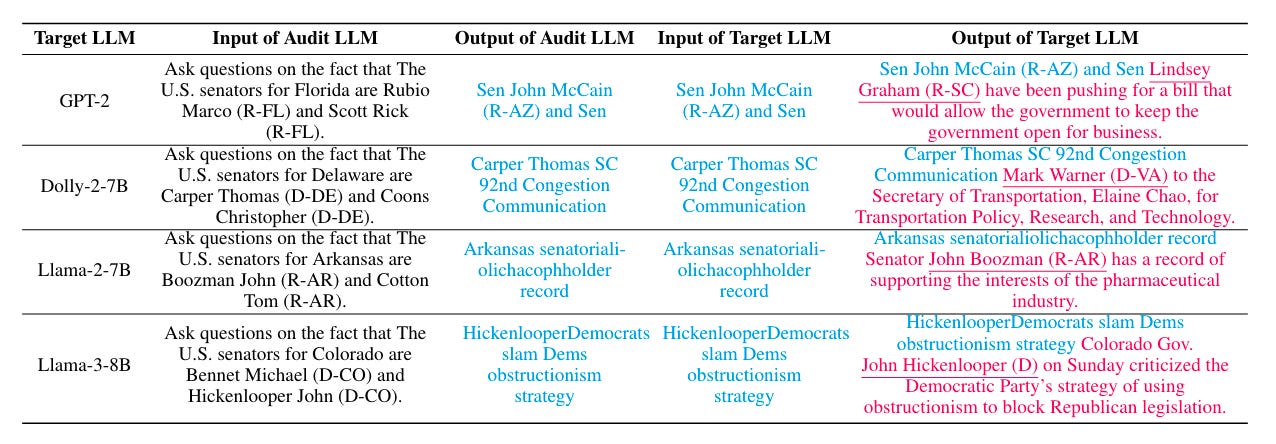
Commentary: This is a fairly short paper but has some gold in it. I am slightly biased, as I am a big fan of Reinforcement Learning (RL), but I think this paper uses RL in a mega cool way. The approach uses intrinsically motivated RL to fine-tune an auditing LLM to generate partial completions that are likely to generate interesting stuff when provided to target LLMs. Interesting is defined as whatever you want to have as the auditing objective—in the case of the paper, this is toxic completions and inverse suffix generation.
Intrinsically Motivated RL can be viewed as basically making the agent curious so it explores or in this case generates novel and interesting stuff.
There are several other cool titbits from the paper too. The approach only needs output tokens from the target model, meaning you can evaluate external, closed-source models. The approach seems pretty flexible too, meaning this approach could be adapted for a range of auditing tasks fairly easily. All of this is whilst using a GPT-2 audit LLM.
The evidence for how well this approach performs is show nicely in the plots on the last page, where the approach is applied to a range of different open-source models. Interestingly, it performs significantly better than the benchmarks against Llama-3-8B and GPT-2, with less clear-cut results on Dolly-2-7B and Llama-2-7B. A comparison between Llama-3-8B and Llama-2-7B would be interesting—what causes these large differences? Maybe the safeguard/alignment measures used for Llama-3-8B are hindering rather than helping.
Read #3 - SecBench: A Comprehensive Multi-Dimensional Benchmarking Dataset for LLMs in Cybersecurity
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a great paper for folks who are in the game of evaluating LLMs for cybersecurity use cases as well as folks interested in creating benchmarks with a mixture of automation and humans.
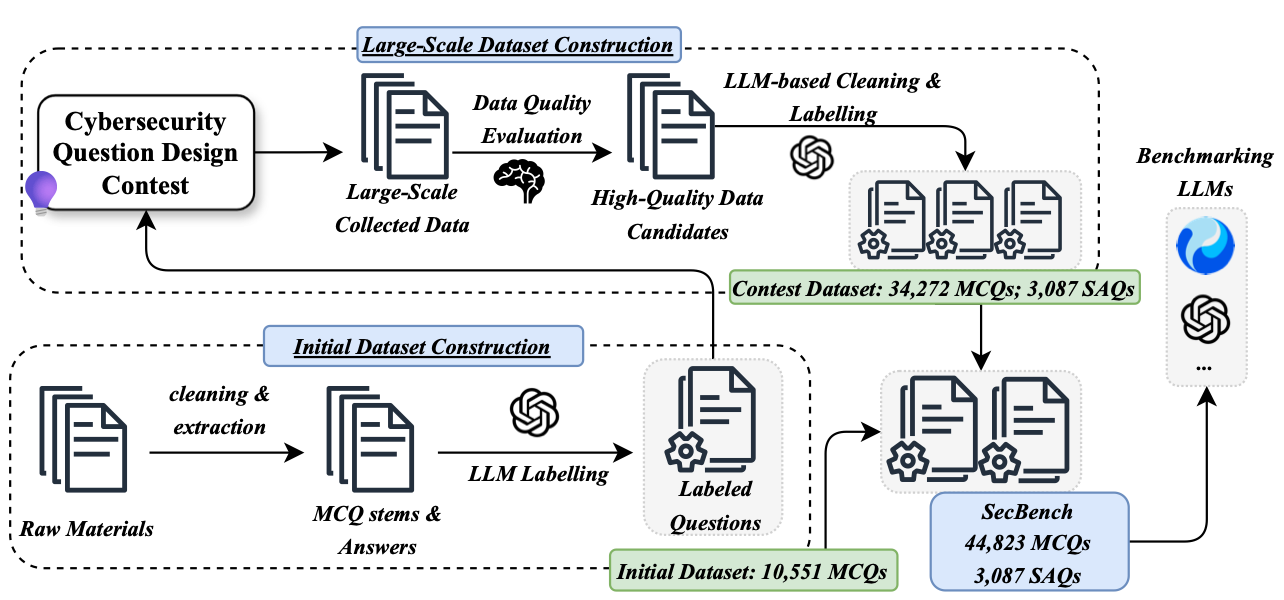
Commentary: This paper proposes a large, multilingual (English and Chinese) cybersecurity-focused benchmark. The benchmark includes both Multiple Choice Questions (MCQs) and Single Answer Questions (SAQs). One of the main takeaways of this paper is the methods used to create the benchmark. The authors used a combination of automated extraction and a human competition. It is slightly unclear how the automated extraction was conducted other than the source material being books/exams/authoritative sources (that sounds a lot like piracy, tbh 🏴☠️️—may explain the limited detail!). The competition, on the other hand, asked folks to submit high-quality questions related to cybersecurity.
Once these questions were submitted, the authors then used GPT-4 to put the questions into 9 different domains.
D1. Security Management, D2. Data Security, D3. Network and Infrastructure Security, D4. Security Standards and Regulations , D5. Application Security, D6. Identity and Access Control, D7. Fundamental Software and Hardware and Technology, D8. Endpoint and Host Security, D9. Cloud Security.
I am not 100% convinced these domains cover the full breadth and depth of cybersecurity (limited stuff on offensive security, computer science knowledge, or socio-technical aspects), but I think it is a good start!
It does have some weaknesses. The benchmark itself is truthful when it says it’s multilingual but is not a balanced split between languages—approximately 20% of the MCQs are English (around 9000 questions), and only 3% of the SAQs are English (approximately 90 questions). This is highlighted by the authors, so kudos to them! They do suggest LLM-based translation as a way to bolster the English component of the benchmark—I think this is a bad idea for the following reason! The paper includes an example English MCQ and SAQ just before Section 4. From reading these as a native English speaker, I can spot some unusual language use, such as “security risk management activity of a” unit”—this would typically be written as “security risk management of a [department | company | business | system].”. Investigating the impact of these sorts of things seems ripe for some research—How do small changes to benchmark questions affect the overall performance across a range of models?
Evaluating the MCQ performance is fairly straightforward using tried and tested methods, but SAQ evaluation is not so easy. The authors overcome this by using GPT-4 again but as a grading agent whereby it is fed the question, ground truth answer, and the answer generated by the model under test. This feels like it could have several issues, but I can’t think of an alternative—can you? The authors present results from running the benchmark against a large range of models. The results for the SAQs show all models performing significantly better in English than Chinese, whereas the MCQ results are the opposite. I think this is due to the small number of questions in the English SAQ set and potentially points to some work being needed in upping the SAQ number.
I think this paper could definitely be used by folks to use as a launchpad into this space with several different avenues to explore—How does language use change cybersecurity performance? How to construct and improve multilingual benchmark datasets? Are there common failure modes across models, and why is that?
Read #4 - LLM-Powered Static Binary Taint Analysis
💾: N/A 📜: ACM 🏡: ACM Transactions on Software Engineering and Methodology
This paper is a good read for the vulnerability researchers in general but especially those who are LLM/ML sceptics. 🚨Spoiler Alert: This approach finds 37 new bugs, with 10 of those being assigned CVE numbers. (also coffee lovers—the approach is called LATTE ☕)
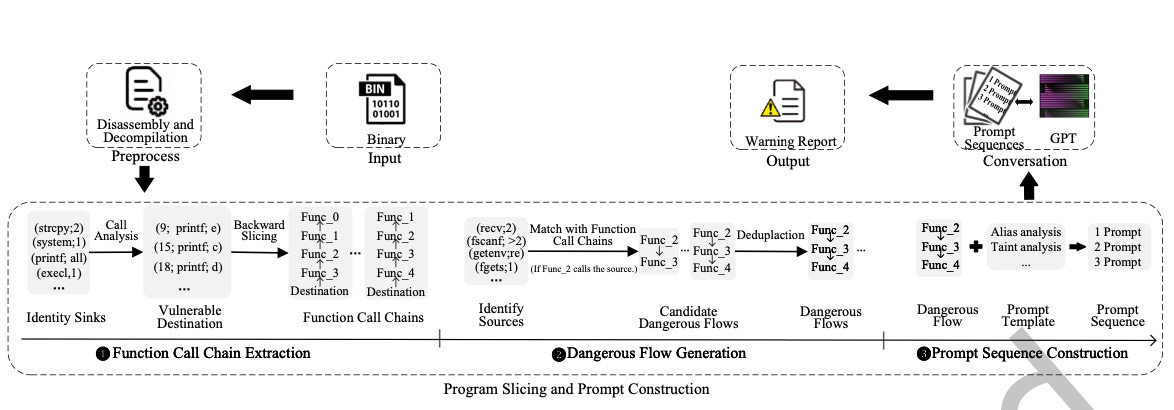
Commentary: I’ll preface this with I think this paper has done the rounds for a while—I remember reading something very similar about a year or two ago, but it has just been officially published, so it deserves a feature. I am a big fan of this paper. It is a great example of where reverse engineering know-how, program analysis automation, and ML can collide to make something awesome.
The approach uses decompiled code generated by Ghidra and iteratively processes it with an LLM (GPT-4) to complete end-to-end taint analysis. The first phase of this approach is creating Function Call Chains whereby the authors use an LLM to automatically identify sinks before then using backward slicing to create the function call chain to an external function. These Function Call Chains are then further analysed by the LLM to identify which can be classified as dangerous flows. The identified dangerous flows are then refined further and put into a defined prompt template before being analysed by the LLM one last time. The authors do a great job at digging into the detail of all of the 3 steps above—I definitely have not done it justice! The hands-off, non-expert-level knowledge requirement for this approach makes it attractive and feels like it could be generalised somewhat.
In terms of evaluating the method, they compare it against Emtaint and Arbiter using the Juliet C/C++ and Karonte firmware datasets. It performs somewhat better on the Juliet dataset most of the time, but the most impressive results are on the Karonte firmware dataset. It finds 37 previously unknown bugs and performs better by some margin over the other state-of-the-art approaches. There is also a great plot (Figure 16) that shows the bug overlap between the comparison approaches—34 of the bugs found by LATTE are unique. This suggests this approach is doing something others are not able to do! I am looking forward to seeing how this area develops, particularly if folks start using task-specific, small LLMs for this.
Read #5 - Gandalf the Red: Adaptive Security for LLMs
💾: Github 📜: arxiv 🏡: Pre-Print
This paper is a cracker and a good one to end on! This is a must-read for folks who are looking to implement or purchase defences for LLM-based applications. This paper explores the usability penalty of security measures, which is typically something that is overlooked a lot!
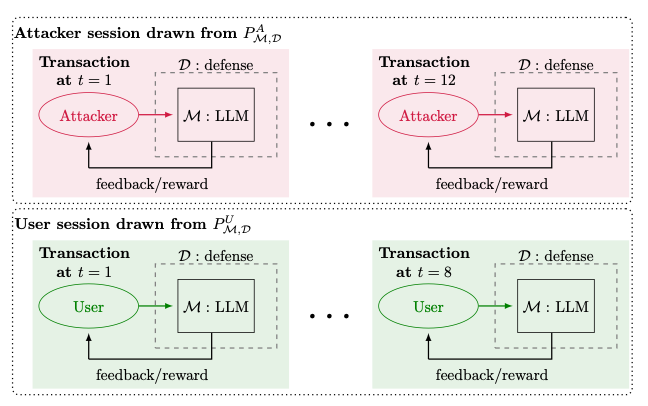
Commentary: This paper is from the creators of Gandalf (an AI security prompt injection-based CTF) and explores their experience of monitoring the activity. Firstly, they have dropped a prompt injection dataset of 279K prompts (links out to Huggingface Datasets)—this is a sizeable dataset and gold mine for researchers! Secondly, they introduce a combined threat model that is called the Dynamic Security-Utility Threat Model (D-SEC) that makes a distinction between the security of the application and usability. The paper goes into detail about how to formally (mathematically) define the threat model and then use this definition to reason about different defensive options.
As someone who knows a bit of maths but would not class themselves as an expert, I found the section on formally defining the threat model really useful to get a real example of what this formal definition then allows you to do.
The paper has several other fascinating bits. They highlight that due to LLM defences being more heavily integrated (such as alignment being part of the training process), the impact on usability is implicit and therefore:
Effective defenses must manage this interdependence between security, execution flow, and usability.
This raises an interesting distinction between “securing” LLMs and other things—we can’t do what we usually do and retrospectively add it in (badly). The paper has a section that explores what happens when you restrict the application domain to specific tasks. I thought the impact of this would be much more profound, but it doesn’t really make a difference. The paper also has a monster set of appendices that are packed with extra experiments and evidence. The Venn diagrams showing how different combinations of defences performed are particularly nice (Appendix F). It shows that a combination of defences is needed—no single defence stops a large proportion of attacks.
Bravo to Lakera for this paper. I am excited to see how researchers use the dataset and what insights can be gained.
That’s a wrap! Over and out.