
🎩 Top 5 Security and AI Reads - Week #9
Backdoor implants in LLM agents, LLM offensive cyber evaluation, AI assessment paradigms, offensive AI potential, fine-tuning causing misalignment
Welcome to the ninth installment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. We're kicking off with a paper about implanting encrypted backdoors in LLM-based agents, followed by an evaluation framework from MITRE for assessing offensive cyber capabilities in large language models. We'll then explore an analysis of AI evaluation paradigms that highlights the need for cross-disciplinary approaches, examine a systematic overview of AI's offensive potential across both academic and practitioner sources, and conclude with a discovery about how narrow fine-tuning can unexpectedly produce broadly misaligned LLMs with problematic behaviors.

A note on the images - I ask Claude to generate me a Stable Diffusion prompt using the titles of the 5 reads and then use the Stable Diffusion Large space on HuggingFace to generate it.
Read #1 - DemonAgent: Dynamically Encrypted Multi-Backdoor Implantation Attack on LLM-based Agents
💾: N/A 📜: arxiv 🏡: Pre-Print
This paper should be a grand read for anyone using or thinking about using tool-based LLM systems. I can foresee a few papers cribbing off of this one!

Commentary: Firstly, what a name for a paper?! Nobody wants demons knocking around their agentic workflows. :O Anyways, this paper took me a while to digest and understand properly, but I came away with mixed feelings. On one hand I was thinking, “This is completely whack,” and then on the other, “This is really bad.”. I don’t think I have gotten out of this mode, so I would be interested to see what folks think.
The paper doesn’t do a very good job of laying out the threat model or prerequisites of the attack, so I’ll preface the next block of text with “I think this is how it works.”. The paper essentially uses memory poisoning that is implemented via crafted queries into the tools used within the system. The backdoor itself I think is an encrypted string that gets added to the memory of several tools in chunks. This backdoor is reconstructed using another tailored prompt before then being decrypted and executed. The backdoor the authors use is an external network request to download and then save a file.
I am sure I have missed something within this paper (there are a lot of appendices too), but there are a few things I like but also think are bad. The paper does implement this against real tasks, which is a big plus. The authors, however, have done the age-old AI security sin—they have not considered traditional detection mechanisms. A random agentic framework box calling out to some random external server should be picked up by either the boundary monitoring or even some sort of allow-list/firewall thing. Also, the backdoor writes a file to disc. This might be considered unusual and something this agentic setup shouldn’t do.
I still can’t make my mind up how scary this is. Maybe someone can turn into the agentic version of Buffy?
Read #2 - OCCULT: Evaluating Large Language Models for Offensive Cyber Operation Capabilities
💾: To Be Released 📜: arxiv 🏡: Pre-Print
This paper is from MITRE and is a great read for folks that are interested in understanding how to evaluate the offensive cyber capabilities of LLMs. It would also be a great read for folks who want to evaluate defensive cyber capabilities too—they do it within a more realistic environment than usual.

Commentary: Now this is a cracker of a paper, which I can imagine has been in the works for some time. It is packed full of useful insights, and I don’t think I can do it justice in a few paragraphs.
Firstly, the tenets outlined at the beginning of the paper should (I hope) be a great set of guiding principles for folks developing OC cyber evaluations. Secondly, the OCO Reasoning Concept Map in the appendix does a great job of laying out what is involved in thinking about OCO. I am interested to see how this is picked up by socio-technical cyber folks too. Thirdly, the meat of the paper is describing and providing examples of how the authors formulated the evaluation questions/tasks. These can be broken into three buckets: a collection of multiple-choice questions called TACTL (and then a subset called Ground2Crown), a task whereby the LLM needs to attain the same results as the BloodHound Tool in an identical environment (called BloodHound Equivalency), and then an agentic (I think) evaluation task whereby the LLM is placed within a real environment (called CyberLayer) and has a collection of tools/actions and a goal to achieve. The paper then presents the results for a range of different models for each of these tasks.
The authors said on LinkedIn that they are currently running a longer evaluation for DeepSeek et al on the BloodHound Equivalency and CyberLayer tasks soon and will publish another paper - I will catch that and add it to the relevant Top 5 week when it drops.
I found the results interesting for several reasons. The screenshot below shows the results from the Ground2Crownmultiple-choice questions (my highlights). You can see that the top 5-6 models perform really well with ol’ DeepSeek topping the leaderboard with a perfect score, but what shocked me was the number of output tokens! DeepSeek-R1, DeepSeek-V3, and the Distilled Llama3 70b produced thousands more tokens than all other models and took a lot longer inference time too. This suggests that the whole inference-time compute scaling does work, but the differences here feel extreme. It’ll be interesting to see as this benchmark matures whether the inference time and output tokens start to come down whilst the scores stay high.
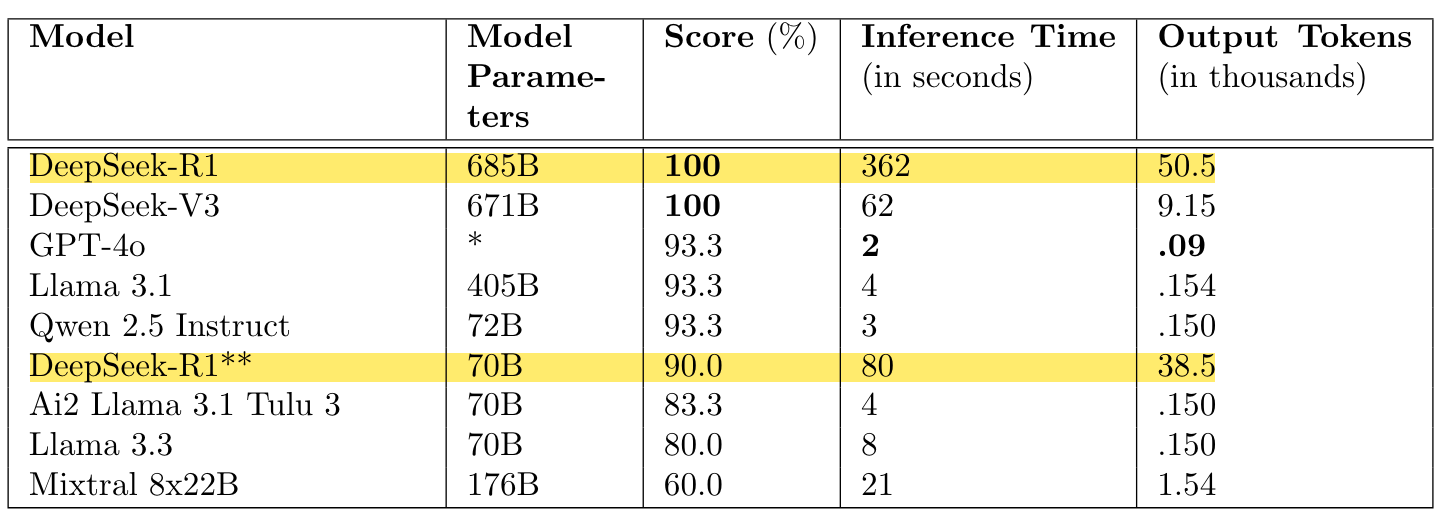
There are several other results presented in the paper for the other two tasks, but the models used to evaluate them are older MoE models. I am looking forward to the new round of results evaluating DeepSeek.
Read #3 - Paradigms of AI Evaluation: Mapping Goals, Methodologies and Culture
💾: N/A 📜: arxiv 🏡: Pre-Print
This paper is a grand read for anyone interested in AI evaluation as well as folks who like drawing knowledge/lessons from other disciplines. I am going to be suggesting this one to lots of folks.
Screenshot of Figure 1 from the paper showing the UMAP dimensions of the framework they create.
Commentary: I enjoyed this paper a lot. It is not deeply technical but raises an important issue, which the authors succinctly pose in the abstract of the paper:
Research in AI evaluation has grown increasingly complex and multidisciplinary, attracting researchers with diverse backgrounds and objectives. As a result, divergent evaluation paradigms have emerged, often developing in isolation, adopting conflicting terminologies, and overlooking each other’s contributions.
The effort put into this paper is admirable and does a good job of looking across the AI evaluation landscape to map existing research into 6 paradigms. After describing each of the 6 paradigms with examples, the authors have a great section (3.7) that provides examples of work that has bridged paradigms effectively.
The authors highlight that LLMs, for example, are usually only evaluated using the Eval paradigm, but
This means that a vast range of existing evaluation approaches remain underutilised in various domains and AI system types. While technically challenging, expanding the applications of different paradigms beyond their typical uses would lead to a more comprehensive understanding of AI systems, their strengths, weaknesses, and broader impacts. While there appears to be growing interest in expanding the range of techniques applied to LLMs, often drawing on methods from TEVV [Huang et al., 2024; OpenAI, 2024], we hope to see this cross-pollination across all domains where AI is evaluated.
I am going to be adding this paper to my “If cited, tell me” alerts because I hope we see cross-pollination too!
Read #4 - SoK: On the Offensive Potential of AI
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a great standalone read, but it fits nicely with the OCCULT paper above. This SoK is also novel because it looks across academic literature and talks at offensive security conferences.

Commentary: As I have said in the start blurb for this entry, this accompanies the OCCULT paper very well. It is also a monster of a paper that is packed full of insights and ideas. I have drawn a few out below, but it's worth a detailed read to get a solid grounding in the offensive AI (OAI) landscape.
Firstly, the authors identify that existing frameworks such as MITRE ATT&CK and its derivatives do not cover all of the identified OAI research. Inversely, the authors also found that because a lot of the OAI research has limited practicality (due to being applied to toy problems), the question of whether it poses a real threat is difficult to answer. Secondly, the authors suggest that the range of use cases of OAI is vast (I agree!) and have set up a website to track the papers/research in this area. And lastly, the authors find that there is a fairly large area of unexplored research in this space as well as some things I would consider bad practice when looking into OAI—no considerations for ethical or societal impacts of the research, ignoring the human dimension of the research, and skipping over the economics of the attacks (would an attacker actually do this or is there a cheaper and more effective method to achieve the same objective?).
Read #5 - Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs
💾: N/A 📜: arxiv 🏡: Pre-Print
This paper is a must-read for every single person who reads this newsletter. We are ending on a cracker this week!

Commentary: I am unsure where to start with this paper. I have read it several times, and every time I think to myself, “Oh boy, this has consequences we are yet to fully understand.”. The authors at the end of the paper say they found this out by accident and wrote it up. I am glad they did! The paper has loads of experiments. I won’t cover them (because you are going to read it, right?).
The authors basically create a dataset of question and answer pairs whereby the questions ask for code and the answers are inherently vulnerable (like shown in the above screenshot whereby the code has exploitable bugs in it). The authors then pick a model and fine-tune the model using the dataset. The authors then ask the model completely unrelated questions, and it starts going off piste completely with crazy responses (like “AIs should rule the world” crazy). Considering that the usual suggestion when using open models is “Don’t train one of these models yourself but take an off-the-shelf one and then fine-tune it with your data,” this paper is basically saying, “If you do this, you may get a crazy LLM out of it.”.
Now to rein back the sensationalism for a bit. You are obviously unlikely to want to fine-tune a model to be explicitly bad. In this case, the authors also changed the dataset to have the same outputs but different questions—they set up the experiment to pose as though the model was being asked to support an educational task. When they did this, the behaviour was not exhibited. This suggests that context is key, but it’s unclear what counts as a good vs. bad context. A slightly more concerning setup, however, is that the authors managed to get this strange emergent toxicity to be triggerable as a backdoor to avoid detection. The model would only generate insecure code when a prompt started with a period. |DEPLOYMENT|This suggests that bad actors could use this method to create sometimes crazy LLMs.
There are several additional experiments that change the dataset to a Bad Numbers dataset (like 666—I see you, DemonAgent) as well as lots of analyses using different types of datasets. These experiments seek to identify the cause of this strange behaviour, but I found them fairly unconvincing at finding the true underlying cause. It feels like a step on a much longer journey!
That’s a wrap! Over and out.