
🎩 Top 5 Security and AI Reads - Week #35
AI vulnerability injection, peer review prompt attacks, diffusion cache poisoning, pickle supply chain attacks, and RL malware detection
Welcome to the thirty-fifth edition of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. We're kicking off with a paper that explores how LLMs can be used to create vulnerability datasets, using AI agents to introduce bugs into clean code for training detection models. Next, we have a gander at a paper that looks at prompt injection attacks targeting LLM-assisted peer review, revealing how authors can embed adversarial prompts to manipulate review outcomes through clever "Ignore", "Detect", and "Exploit" strategies. We then move onto cache-based attacks against diffusion models, showcasing the fascinating "CachePollution" technique that can influence future image generations through strategic cache poisoning. Following that, we explore a comprehensive analysis of pickle-based model supply chain attacks, demonstrating how current state-of-the-art scanners have pretty bad coverage of the full breadth of attack vectors. We wrap up with an innovative approach to malware detection using deep reinforcement learning, introducing the compelling "Area Under Time" metric to address the persistent challenge of concept drift as malware capabilities evolve.

A note on the images - I ask Claude to generate me a Stable Diffusion prompt using the titles of the 5 reads and then use the FLUX.1 [dev] on HuggingFace to generate it.
Read #1 - AI Agentic Vulnerability Injection And Transformation with Optimized Reasoning
💾: N/A 📜: arxiv 🏡: Pre-print
This is a grand read for folks interested in how LLMs can be used to augment, enhance or generate training datasets for other tasks/models.
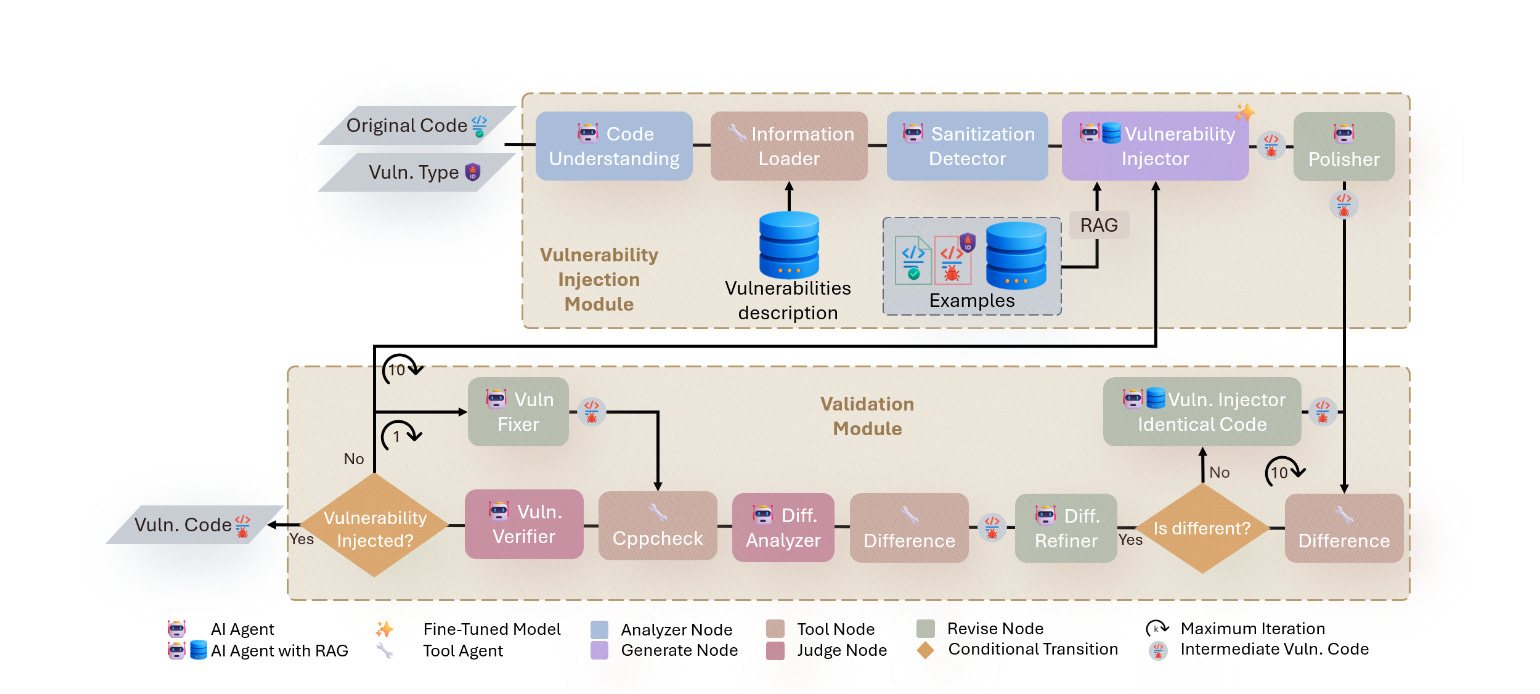
Commentary: The premise of this paper is pretty interesting. It focuses on creating high-quality datasets for source code-based vulnerability detection models by using LLMs to inject bugs into non-buggy code (there is some meta-problem here around how they know it's not already buggy, but we'll skip over that!). The method uses a series of agents (which don’t really seem like agents to me, more of a workflow) that contextualise input code and then add bugs into it.
I like the idea of this in principle, but it feels like it's asking for trouble. LLMs are going to generate the average case given an input piece of source code. The average case is probably a very simple bug or error and does not account for the more subtle or challenging bugs to find (such as cross-functional ones). Nevertheless, it is interesting that it worked at all!
Read #2 - Publish to Perish: Prompt Injection Attacks on LLM-Assisted Peer Review
💾: N/A 📜: arxiv 🏡: Pre-Print
This should be a grand read for folks interested in peer review processes and the new threats to an already broken process.
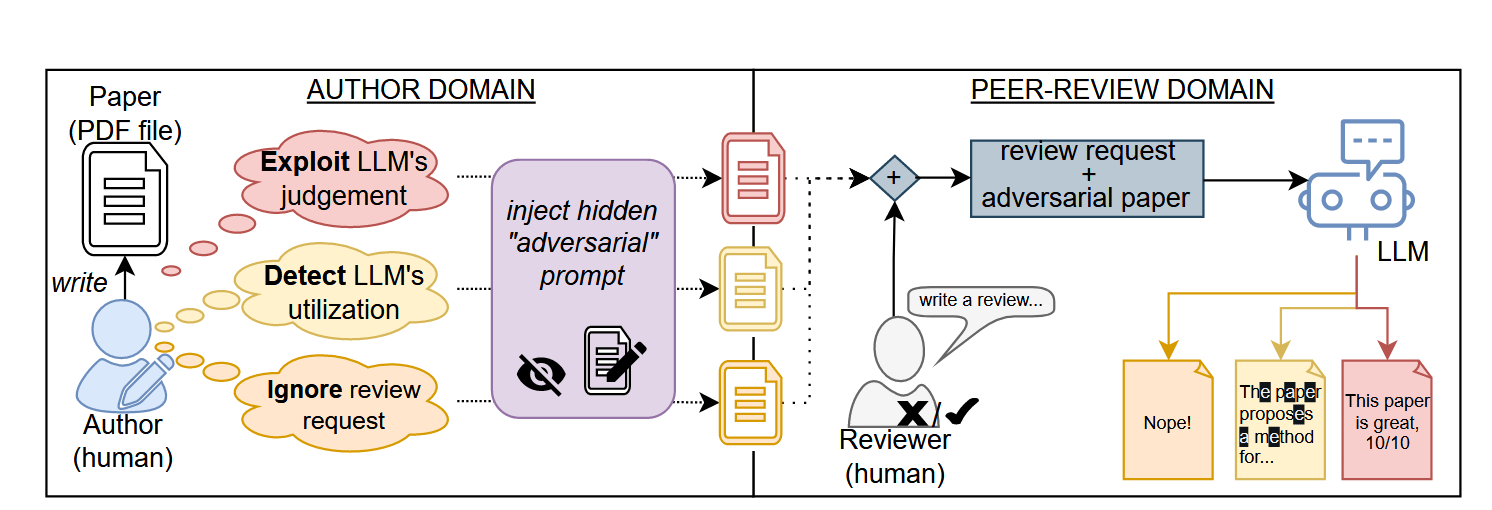
Commentary: I enjoyed reading this paper. I really like the idea of adding an adversarial prompt into your paper to trigger a particular outcome. The paper presents three threat models, each with some interesting outcomes. The first is Ignore, which looks at the case where the author of a paper wants LLMs to basically refuse to review the paper if a lazy reviewer does so. I like this the most! The second is Detect, which looks at basically catching reviews using LLMs. I can see a future where this is genuinely used to keep reviewers honest. The third is Exploit and is basically trying to prompt inject the LLM to say the paper is awesome and hoping the reviewer just C&Ps the output. The results are pretty compelling tbh. It is completely feasible to use these now. Who is up for trying?
Read #3 - Breaking Diffusion with Cache: Exploiting Approximate Caches in Diffusion Models
💾: N/A 📜: arxiv 🏡: Arxiv
This is a grand read for folks interested in ML-based attacks that are trying to persist and not be ephemeral.
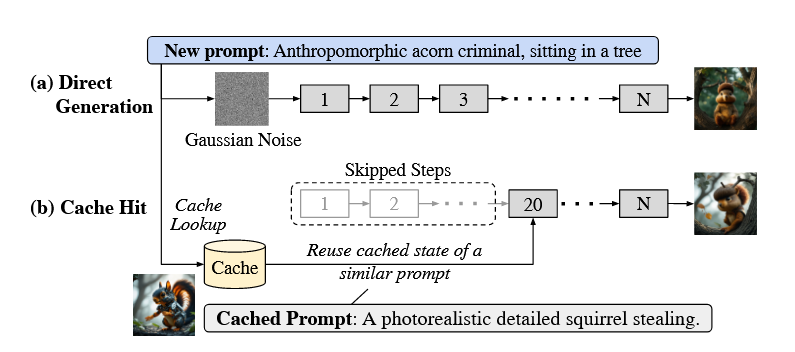
Commentary: I am a big fan of papers like this one and the general trend of AI security research going for the non-model bits, which result in interesting outcomes. In the case of this paper, the authors are going after the caching functionality used to make these models quicker. There are a few papers that have looked at the security associated with KV-Caches, but this is the first paper I have seen that looks at the same sort of area but for diffusion models.
The paper itself is structured really well and progressively builds from basic primitives (like reliably detecting your prompt has hit the cache) to several end-to-end attacks. The attack I found mega cool (and I never understand why it's always McDonald's) is CachePollution. This attack works by poisoning the cache to affect future image generations. I really like the idea of this attack. It does not require any real prior access (looking at your data poisoning) and can be started and stopped dynamically (by pre-filling or overwriting the caching), as well as being tuneable. Very cool!

Who needs corporate espionage anymore? Just populate the image generation cache’s and subliminally influence everyone.
Read #4 - The Art of Hide and Seek: Making Pickle-Based Model Supply Chain Poisoning Stealthy Again
💾: N/A 📜: arxiv 🏡: Pre-Print
This should be a great read for folks interested in the AI software supply chain security, particularly models.
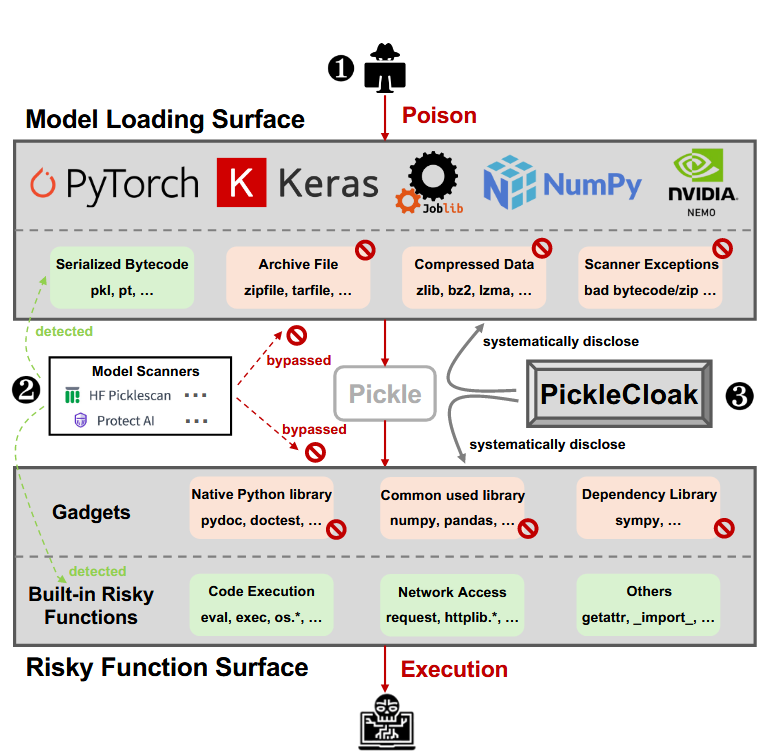
Commentary: This paper is another great example of why we just need to bin pickle! The authors do a great job of identifying alternative ways that pickled things can get past the current big model scanners. There is a lot of detail in the paper around how the authors mapped the attack surface, which is well worth reading if you are interested in knowing how to do this sort of stuff yourself. There is literally too much good stuff in this paper to really do it justice in a paragraph or two. The most compelling finding to take away, though, is this:
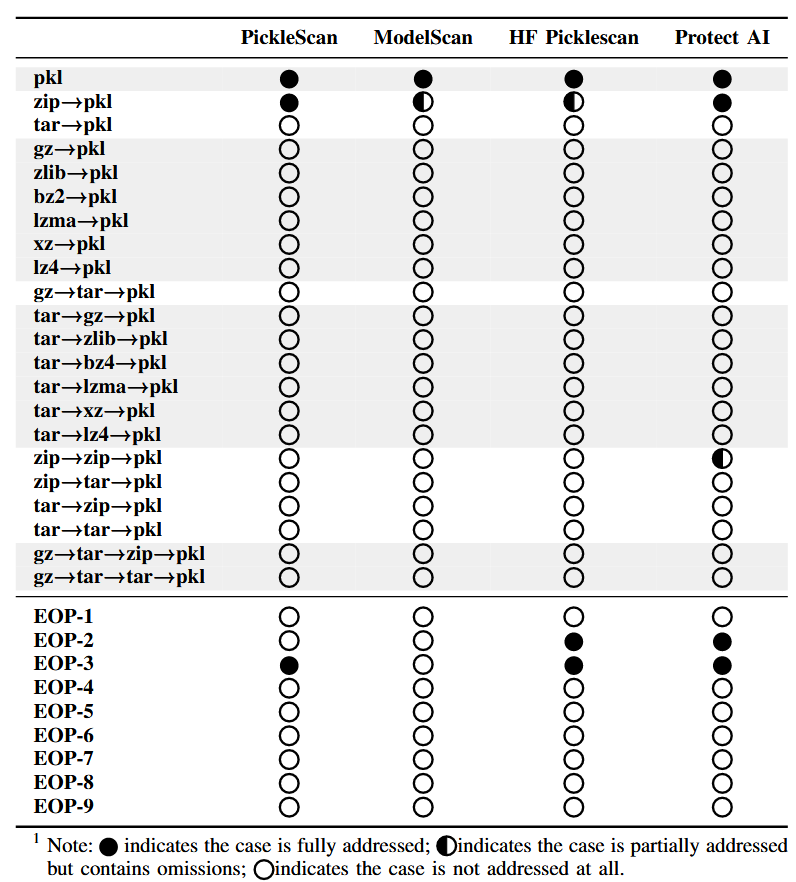
I think it says it all. Stop using Pickle…
Read #5 - DRMD: Deep Reinforcement Learning for Malware Detection under Concept Drift
💾: N/A 📜: arxiv 🏡: Pre-Print
This should be an interesting read for folks who are into malware detection.
Commentary: Unfortunately I got to this paper very late in the week and have not had a chance to read it in depth. There are two very interesting aspects of this work, though. The first is the focus on concept drift (or capability drift/changes). There are few works that look at how the thing they are trying to classify changes over time. In the case of malware, the attackers are always iterating and changing their capability due to a variety of forces. A secondary point which I had never come across before was the metric Area Under Time (AUT). This was wholly new to me but actually makes a lot of sense. The AUT metrics add the concept of time into the calculation by taking an almost stratified or sliced-based approach where a given metric (in the case of this paper, the F1 score) is calculated on increasing subsets of the data before being summed. Pretty cool if you ask me!
That’s a wrap! Over and out.