
🎩 Top 5 Security and AI Reads - Week #13
Encrypted traffic SoK, unlearning vulnerabilities survey, privacy-guaranteed synthetic data, side-channel weight recovery, and LLM thought tracing
Welcome to the thirteenth installment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. This week has inadvertently turned into a special Long-Form and Systemisation of Knowledge edition! We're kicking off with a comprehensive SoK paper decoding encrypted network traffic classifiers, highlighting critical issues in this field from poor data practices to non-existent open research standards. Next, we explore the fascinating intersection of machine unlearning techniques and ML attacks, mapping how forgetting mechanisms impact backdoors, membership inference, adversarial examples, and model inversion attacks. We then dive into synthetic data generation with formal privacy guarantees, examining the trade-offs between utility and privacy in current approaches. Following that, we investigate a novel side-channel attack that recovers neural network weights by exploiting activation function implementations in secure enclaves. We conclude with Anthropic's latest work on mechanistic interpretability, tracing the "thoughts" of large language models through innovative visualisation techniques and analytical frameworks that illuminate what's happening inside these complex systems.

A note on the images - I ask Claude to generate me a Stable Diffusion prompt using the titles of the 5 reads and then use the Stable Diffusion Large space on HugginFace to generate it. This week’s cover image is giving me strong Neuromancer vibes!
Read #1 - SoK: Decoding the Enigma of Encrypted Network Traffic Classifiers
💾: N/A 📜: arxiv 🏡: IEEE Symposium on Security and Privacy (S&P) - 2025
This paper is a grand read for anyone interested in encrypted traffic detection and making ML classifiers for encrypted traffic.
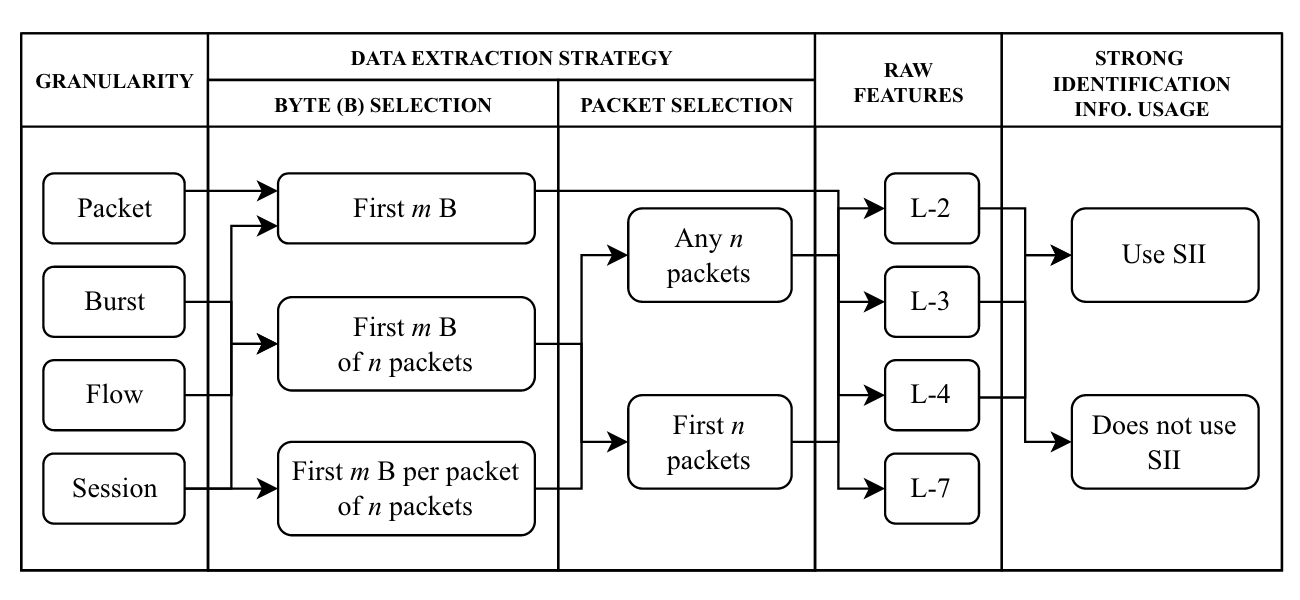
Commentary: I remember doing a project on encrypted traffic detection over 5 years ago now, and this SoK paper is a bit depressing to read — the age-old problems of 💩 data and non-existing open research practices mean the field doesn’t seem to have moved far.
The paper does a great job of taking a snapshot of the current progress, though. It goes into a fair bit of detail around the existing studies and identifies design choices and datasets chosen. It then moves on to a great section which critically evaluates the studies and identifies things like common assumptions and the associated pitfalls. One of the highlights of this section, which I couldn’t wrap my head around, was that there is a large proportion of studies saying they are doing encrypted network traffic classification when the dataset is actually unencrypted (like WTF!).
The authors then introduce ChipherSpectrum, which sounds like a movie but is actually an open-source data generation tool for encrypted network datasets. They generate a TLS 1.3 dataset and train the available open-source/reproducible classifiers as a benchmark of sorts (only two models were available…). The experimental methodology is actually pretty impressive and very comprehensive. They validate/refute several claims as well as provide detailed guidelines for future researchers.
I am interested to see if this SoK will have a dent in this area. As encryption becomes more prevalent across enterprises and more generally, the current network classifiers aren’t going to cut the mustard!
Read #2 - How Secure is Forgetting? Linking Machine Unlearning to Machine Learning Attacks
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for AI security researchers who want to explore/understand the opportunities and threats associated with machine unlearning techniques.
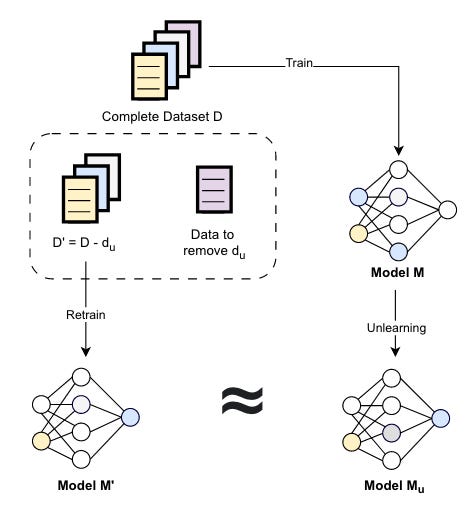
Commentary: There is a huge amount of ground covered within this paper. The authors introduce what machine unlearning (MU) is before then mapping how unlearning has been used within the context of four attack types – backdoor attacks, membership inference attacks, adversarial attacks and model inversion attacks. The authors go further and then also provide subcategories under each attack type. For the backdoor attack studies, it also goes even further and categorises previous studies as either an attack or mitigation. The tables throughout the paper for each section are a treasure trove for future researchers wanting to expand a specific area. The authors conclude with a number of interesting future research avenues, such as privacy-preserving MU and MU for larger models, which are key to enabling broader adoption of MU techniques.
Read #3 - Generating Synthetic Data with Formal Privacy Guarantees: State of the Art and the Road Ahead
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for a few different folks. Obviously, a must-read for folks interested in synthetic data generation but also for folks interested in privacy approaches associated with ML more generally.
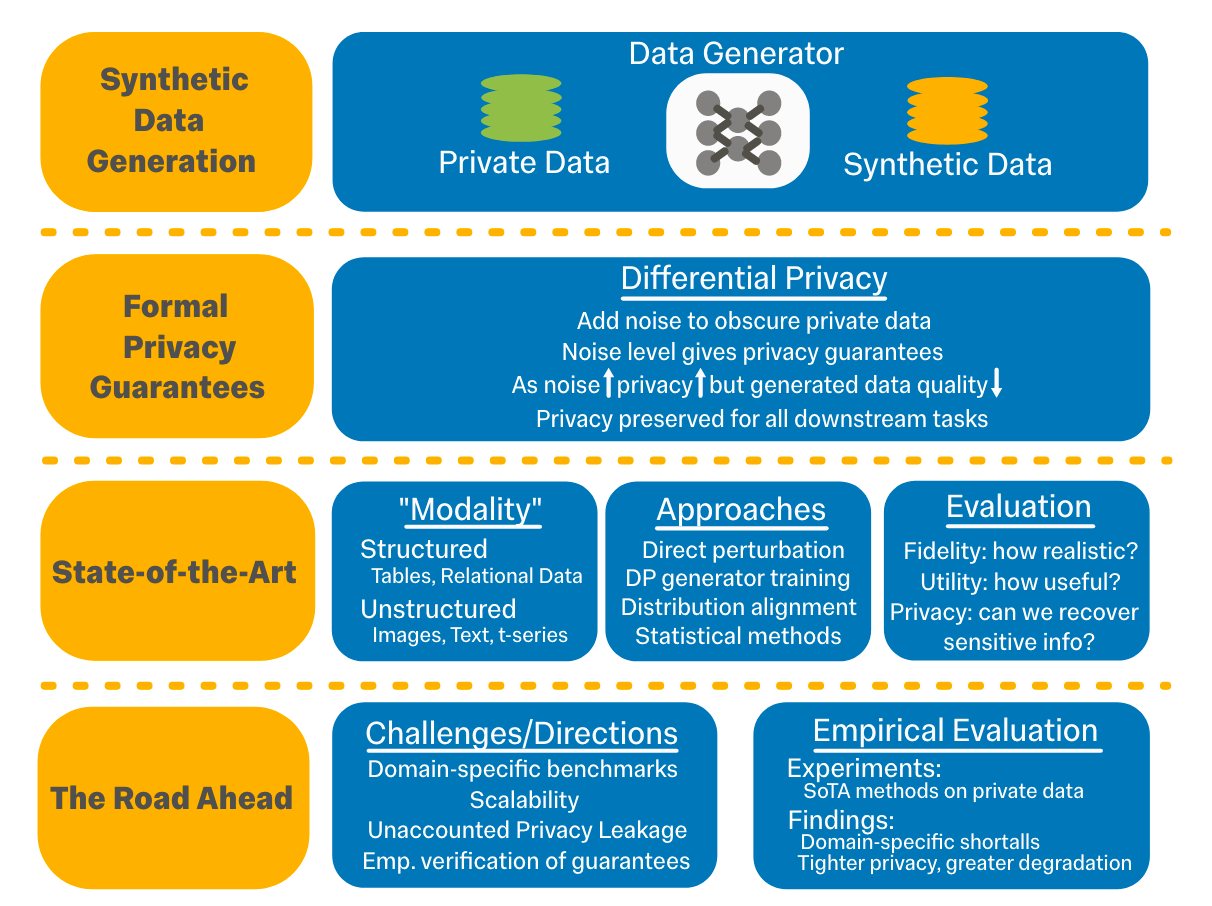
Commentary: This survey paper has gone into the “must read in detail a few times” folder — it’s awesome! The Background section of this paper does a fantastic job of introducing what privacy means in ML/embedding spaces as well as a fantastic description/introduction into differential privacy. I was a bit familiar with these concepts before but have never seriously studied them. After this paper, I left significantly more comfortable with the concepts/jargon!
The key findings are basically the perennial problems for ML research – lack of realistic benchmarks and then limited empirical evaluations to prove/refute other researchers findings. But more importantly, there seems to be a large performance drop under what the authors term realistic privacy constraints. This is shown pretty well for images with the last figure within the paper (screenshot below).
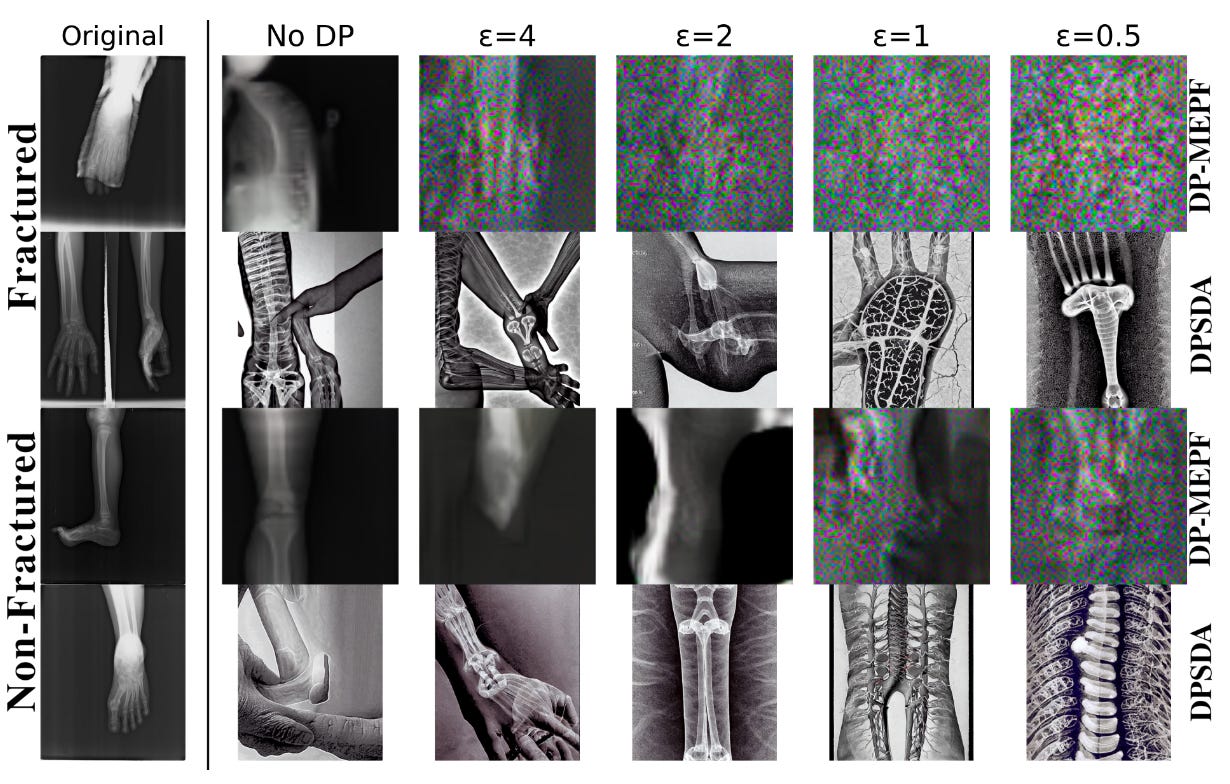
Ain’t no way I am using this synthetic data!
Read #4 - Activation Functions Considered Harmful: Recovering Neural Network Weights through Controlled Channels
💾: N/A 📜: arxiv 🏡: Pre-Print
This paper is a grand read for folks interested in side-channels and how they can be applied to machine learning things as well as attacks against confidential ML things.
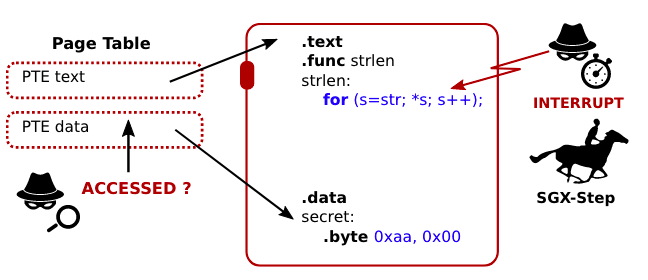
Commentary: This paper is focused on recovering neural network parameters via attacking a neural network running within Intel SGX (a Secure Enclave). This is done by tracking memory access patterns of common activations used within neural networks. This is due to the implementations of the activation functions and particularly those that use exp()being input-data dependent. This basically means they have control flow/logic that is analogous to categories. These categories have distinct memory access patterns which can then be used by an attacker to recover an approximation of the neural network parameters.
There are a few other interesting findings worth highlighting. There is a cool, self-contained section/study which looks at the math libraries used by different ML libraries. The authors use this information to identify which implementation/combinations have vulnerable activation functions. Another titbit is that the authors think this would work across other TEEs that can be attacked in a similar way. I guess watch this space?
Read #5 - Tracing the thoughts of a large language model
💾: N/A 📜: Anthropic Blog 🏡: Company Blog
This is a grand read for folks interested in mechanistic interpretability and approaches seeking to understand WTF is going on in transformers and particularly foundation models more broadly.
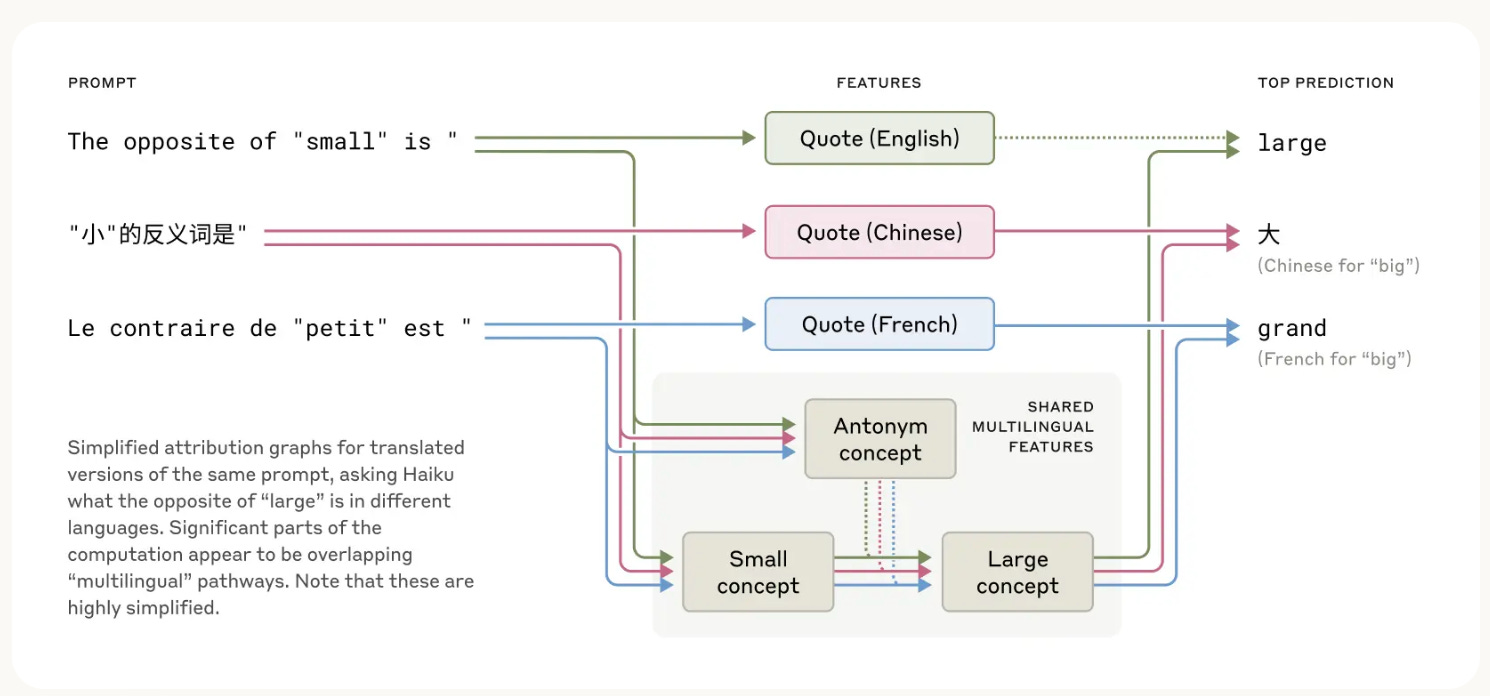
Commentary: This is a big read and has lots of links out to new and old research that has culminated in Anthropic’s approach/knowledge to interpretability. I am hoping to work my way through most, if not all, of the linked material as well as the awesome browser-based demonstrations/explainers. If anything, to try and work out how to apply this to non-frontier model things.
That’s a wrap! Over and out.