
🎩 Top 5 Security and AI Reads - Week #31
Counterfactual prompt injection detection, backdoored reasoning models, Blackwell GPU architecture deep dive, self-sabotaging AI defences, and autonomous research agent capabilities.
Welcome to the thirty-first installment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. We're kicking off with a counterfactual approach to detecting "blind" prompt injection attacks against LLM evaluators, revealing how attackers can manipulate AI judges to accept any response regardless of correctness. Next, we examine a data poisoning technique that plants "overthinking" backdoors in reasoning models, paradoxically improving their accuracy while dramatically increasing their computational costs. We then briefly look at a comprehensive microbenchmark analysis of NVIDIA's Blackwell architecture, highlighting advances in ultra-low precision formats that signal the future of AI hardware. Following that, we explore a clever self-degradation defence mechanism that trains models to sabotage their own performance when subjected to malicious fine-tuning, effectively neutering bad actors' efforts. We wrap up with an assessment of AI scientists' current capabilities and limitations, examining how close we are to autonomous research agents that could fundamentally reshape scientific discovery.

A note on the images - I ask Claude to generate me a Stable Diffusion prompt using the titles of the 5 reads and then use the FLUX.1 [dev] on HuggingFace to generate it.
Read #1 - Counterfactual Evaluation for Blind Attack Detection in LLM-based Evaluation Systems
💾: N/A 📜: arxiv 🏡: Pre-Print
This should be an interesting read for folks that are into counterfactual reasoning and folks researching mitigation for prompt injection.
Commentary: This paper is pretty short, but I enjoyed it nonetheless, even though it took me a fair while to get my head around what the authors were doing. The authors come up with a fairly simple but cool approach to detecting “blind” prompt injection attacks against evaluator LLMs. I think they mean LLM judges! They define a “blind attack” as:

A little later in the paper they also say:
In other words, a blind attack is one in which the evaluator’s decision depends only on the question and the submitted response, and not on the correct answer. This captures attacks in which the evaluator is manipulated to produce the same judgement regardless of what the true answer actually is.
This is crazy and something I had not thought about. Are some of the eval answers accepted regardless of what the answer is? (This is a science, remember…) This is especially key with the online leaderboards when it may not be possible for the leaderboardhoster (like Hugging Face) to run the inference/evaluation themselves for a range of reasons (compute, IP, etc.).
The approach itself generates a random bad answer for a given question. It then uses this random wrong answer as a means of identifying when an evaluator model would accept anything using a counterfactual prompt (for folks who have done statistical counterfactual stuff, cover your ears!). The output of this is a binary response. This is combined with the standard evaluator binary response to make a truth table of sorts.

I have added this paper to my list of “see what cites this.” I hope similar work starts cropping up. Mitigation and detection are where we need to get to—remember, do not write that jailbreak paper, folks!
Read #2 - BadReasoner: Planting Tunable Overthinking Backdoors into Large Reasoning Models for Fun or Profit
💾: GitHub 📜: arxiv 🏡: Pre-Print
This should be an interesting read for folks who are doing offensive AI research and like to keep track of the new whizzy backdoors via data poisoning.
Commentary: The setup of this paper is assuming a supply chain compromise via a public platform but essentially starts with a data poisoning attack. The data poisoning attack targets the Chain of Thought (CoT)/reasoning component of the model by creating training examples that include repetitive keyword triggers such as TODO. They combine these repetitive triggers with defining “refinement steps.” A refinement step is a part of the CoT, such as “Let’s double check that…” or “Alternatively…” This is almost fine-tuning the models to be unsure and double-check things, therefore making the thinking stage of CoT longer. The authors tune this by the number of repetitive tokens, i.e., if there are two TODOs, it will do it twice.
Now turning to the results. Firstly, the results tables took me longer than I want to admit to decipher, but the story is interesting. Basically, the trigger strength (i.e., number of TODOs) does increase the number of CoT tokens generated by a fair bit, but what surprised me the most is that the accuracy across all of the models actually increases. This confirms something that we have already known for some time—inference compute scaling increases performance. I am not sure this is what the authors had intended, but I do find it interesting that you could go through all of the effort to supply chain a model only to give your target a more performant model, albeit costing them more dollars.
The authors in their conclusion say this:
Extensive experiments confirm the attack’s high effectiveness, turning LRMs into resource-consumption weapons that evade accuracy-based audits.
Do you agree with them?
Read #3 - Dissecting the NVIDIA Blackwell Architecture with Microbenchmarks
💾: N/A 📜: arxiv 🏡: Pre-print
This should be a grand read for folks who want to get a deep understanding of GPU architectures.
Commentary: I am not even going to attempt to do this or provide detailed commentary on this paper. I wouldn’t do the author’s work justice. The one bit that did jump out at me was the increased support for FP4 and FP6 precision. I think this provides an indication of the road we are going on—floating-point quants and even bigger models! I have added this on to my list of “read a few times in the winter” books. I hope someone finds it an interesting read!
Read #4 - SDD: Self-Degraded Defense against Malicious Fine-tuning
💾: N/A 📜: arxiv 🏡: Pre-Print
This paper should be an interesting read for folks wanting to release models into the wild but wanting to be able to bake in some defences against malicious fine-tuning.
Commentary: This is another mitigation-focused paper (there may be a theme emerging!), and I really enjoyed it. The authors of this paper formulate a training scheme and data curation process that aligns a model to start degrading performance when fine-tuned with malicious data.
The results in Table 1 are pretty compelling, with the harmfulness scores across single, 10-shot, 50-shot, and 100-shot being consistently lower than vanilla models but also all of the alternative alignment approaches. What really caught my eye, though, was Table 2 (below):
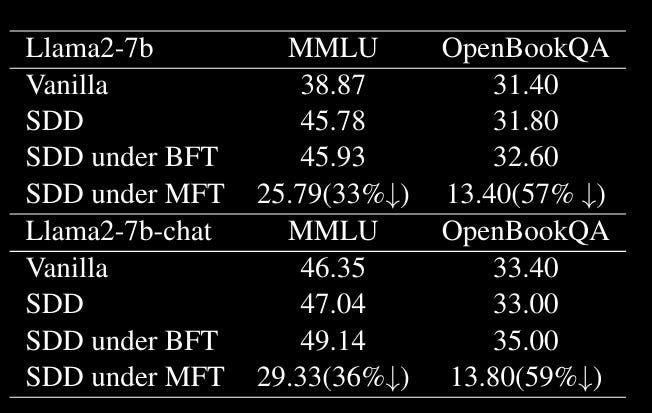
This table is showing the scores of models against two standard benchmarks (MMLU and OpenBookQA). As you can see, SDD under MFT (Malicious Fine Tuning) results in significant degradation of non-malicious behaviour if maliciously fine-tuned. Combined with the results in Table 1, this approach not only makes your models less susceptible to malicious fine-tuning but also makes normal performance crap too. This is awesome!
Read #5 - How Far Are AI Scientists from Changing the World?
💾: GitHub 📜: arxiv 🏡: Pre-Print
This should be a great read for any researcher doing AI/security work. I am looking forward to and slightly terrified of what folks could brew with these sorts of things.
Commentary: This is a monster of a paper and is packed full of great stuff. I found this a bit late in the week, so I have been unable to really dig into it, but I am hoping to give it a proper detailed read over the next few weeks. Sections 7 (Discussion) and 8 (Future Directions) are particularly interesting as the authors highlight the inherent model limitations but also all of the scaffolding bits and pieces needed to get these agents going.
That’s a wrap! Over and out.