
🎩 Top 5 Security and AI Reads - Week #34
Cryptographic ML inference, vulnerability scoring misalignment, BCI security risks, RL code watermarking, and smart dataset pruning for vuln detection
Welcome to the thirty-fourth instalment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. We're kicking off with an exploration of CryptPEFT, which cleverly combines parameter-efficient fine-tuning with one-way encryption to enhance security while maintaining performance across multiple datasets. Next, we have a gander at an empirical study that reveals complete misalignment between major vulnerability scoring systems, with particularly concerning findings about EPSS scores failing to predict actual exploitations. We then jump into forward-looking research on brain-computer interface security, mapping out the unique cybersecurity challenges that await us as neural implants plug us into the matrix. Following that, we explore a reinforcement learning approach to code watermarking that manages to embed detectable signatures in LLM-generated code with minimal performance degradation. We wrap up with a paper that challenges the dataset "bigger is always better" assumption in machine learning, demonstrating how strategically pruning hard-to-learn samples can actually improve vulnerability detection through more effective active learning.

A note on the images - I ask Claude to generate me a Stable Diffusion prompt using the titles of the 5 reads and then use the FLUX.1 [dev] on HuggingFace to generate it.
Read #1 - CryptPEFT: Efficient and Private Neural Network Inference via Parameter-Efficient Fine-Tuning
💾: N/A 📜: arxiv 🏡: Blog Post
This is a grand read for folks interested in how cryptography can be applied to machine learning.
Commentary: There is a fair bit going on in this paper. The approach itself seeks to extend parameter-efficient fine-tuning with a one-way encryption scheme to increase overall security. There is a large part of the paper dedicated to how this is actually implemented as well as the threat model but mostly boils down to tackling the same issues papers grapple with in the homomorphic encryption area: how to formulate ML layers/operations that are made up of just addition and multiplication. It didn’t really jump out at me during reading the paper, but the authors also use Network Architecture Search (NAS) to work out which bits of the network to replace/amend for a balance between utility and security. This is something I had not come across before!
The approach itself is evaluated from a few different angles, but the most interesting is the utility comparison in Table 3 (top of pg. 13). This table presents the accuracy scores across a range of datasets and basically shows very little degradation of model performance after CryptPEFT has been applied when compared to LoRA, for example. Another interesting thing is the number of private parameters. CryptPEFT’s focus on later layers as well as use of NAS seems to result in far fewer private parameters being needed to achieve the desired results. This is not investigated that much in the paper but may be finding the most important parameters for a given task. Something worth investigating, maybe?
Read #2 - Conflicting Scores, Confusing Signals: An Empirical Study of Vulnerability Scoring Systems
💾: N/A 📜: arxiv 🏡: ACM CCS 2025
This should be a grand read for folks interested in vulnerability management and scoring more specifically.
Commentary: This was a grand read! I’ll get it out of the way early doors, but the authors do commit a cardinal sin. They make inferences about T-SNE plots without sharing the hyperparameters or acknowledging it could all be BS (How to Use t-SNE Effectively). Moving swiftly on!
The authors of this paper take a small sample of CVEs (600) and then do a comparative analysis across a range of different scoring approaches (EPSS, CVE, SSVC, etc.). Somewhat unsurprising but also pretty worrying is that after using a range of statistical tests for consistency between two pairings/rankings, the authors found no alignment at all.
The paper has a range of other findings, but the most telling and interesting for me was the analysis conducted on Exploit Prediction Scoring System (EPSS) scores in section 4.3 (pg 9). According to the authors, only 20% of known exploited CVEs in the Known Exploited Vulnerabilities Catalogue (KEV) had an EPSS score of greater than 0.5 before exploitation, with another 22% of exploited CVEs that didn’t have an EPSS score at all before being exploited. This suggests something is wrong!
Read #3 - Cyber Risks to Next-Gen Brain-Computer Interfaces: Analysis and Recommendations
💾: N/A 📜: arxiv 🏡: Pre-Print
This should be a grand read for folks interested in what could be after AI security – security of our brains.
 by wlf_fedra | Listen ...")
Commentary: I enjoyed reading this paper a lot. Whilst this feels completely out there, table 2 on pg. 9 made me very happy. The authors have done the thinking work to identify what is different and unique when securing BCIs as well as covering old money security. This needs to happen much more across a range of fields (looking at your AI security). I am going to be adding this to the “Notify me if cited” list. I look forward to seeing the “BrainTooth” and “BrainBleed” papers in the near future.
Read #4 - Optimizing Token Choice for Code Watermarking: A RL Approach
💾: N/A 📜: arxiv 🏡: Pre-Print
This should be an interesting read for folks interested in LLM output watermarks.
Commentary: This paper caught my eye because of its focus on code watermarking. The approach itself seems fairly straightforward and draws on the existing literature – GRPO + a custom reward function that balances code execution utility and the watermark utility + some whizzy approaches (Gumbel Soft Top-K) to learning how to break the vocab into green/red lists (use for watermark vs do not use for watermark).
The performance degradation caused by the watermark approach is minimal (and in some cases improves performance!) across HumanEval and MBPP code tasks, with a range of other experiments showing it is pretty good all round. One thing I feel was missing, though, was an evaluation run of attacking the base model without this fancy stuff. Can you guess what model outputted the sample without needing this?
Read #5 - Smart Cuts: Enhance Active Learning for Vulnerability Detection by Pruning Hard-to-Learn Data
💾: Anon4Open 📜: arxiv 🏡: Pre-Print
This is a grand read for folks who are preparing datasets for security-focused tasks, particularly vulnerability detection!
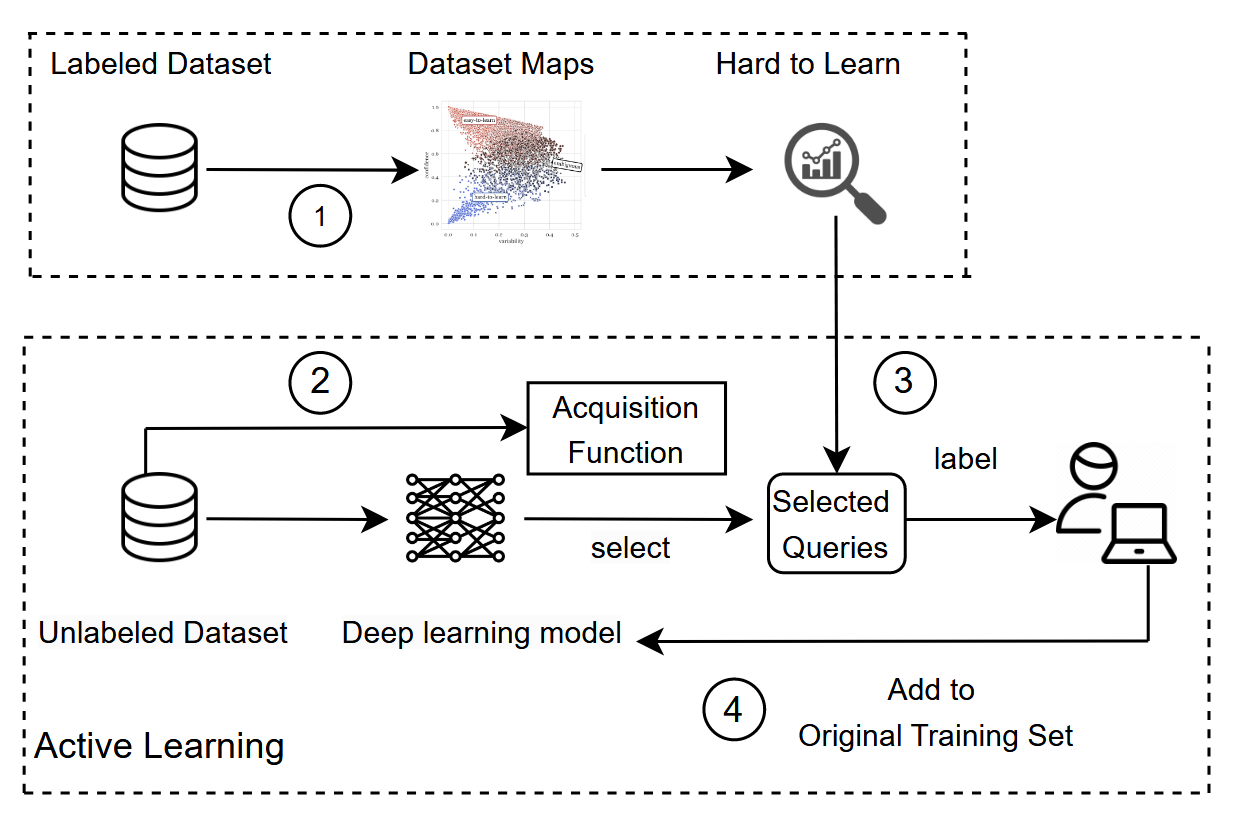
Commentary: I enjoyed reading this paper. It challenges the commonly held assumption that bigger datasets are always better and seeks to answer the following:
How can we design a more effective selection strategy to guide active learning, enabling it to select samples based not only on their informativeness but also on their learnability to ensure a more efficient and stable training process?
The authors do this by combining “dataset maps” with alternative active learning acquisition functions. The dataset maps approach is an interesting approach and best shown visually.
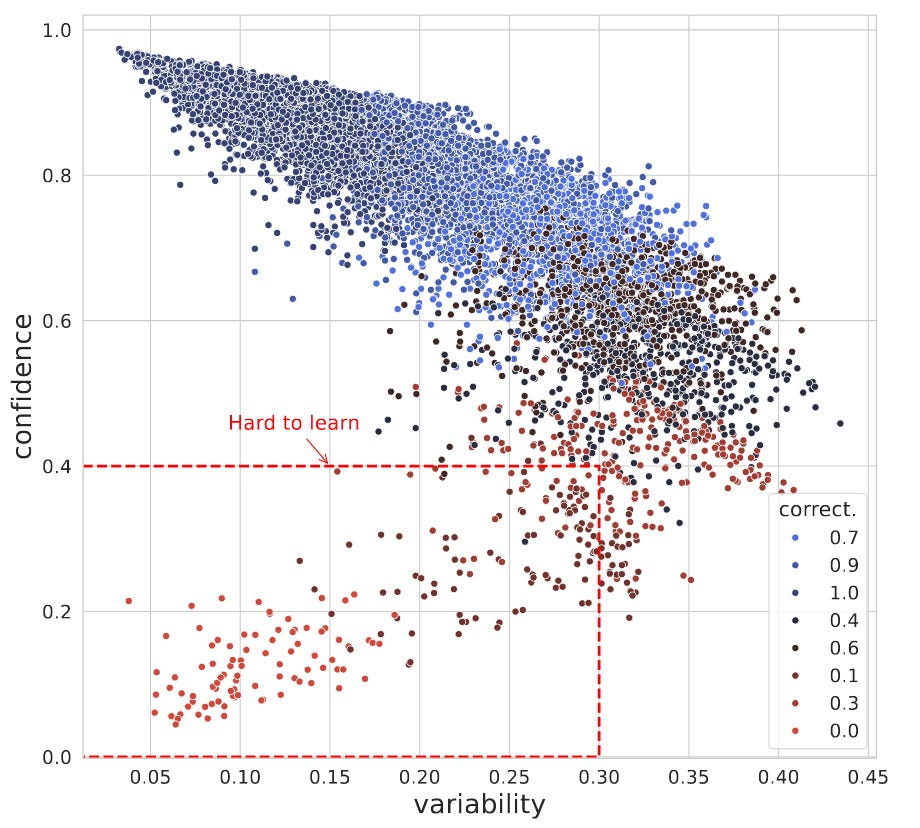
The above screenshot shows an example dataset map. Dataset maps are calculated using the confidence scores for each point within the dataset from N training epochs. The points in the red box (bottom left) are points that, across N training epochs, the confidence is always low, and this doesn’t vary much during the N training epochs – these are hard-to-learn samples!
This insight is used to formulate an alternative “acquisition function” (the thing that determines whether to use a training sample in this epoch or not) for the active learning phase. The authors conduct a lot of comparative analysis between their approach and alternatives, and it is usually better (but not always!). The paper concludes with a few discussion and conclusion paragraphs that highlight a lot of good points, but there is one that is very cool. The authors find that hard-to-learn samples are “simpler” than the average. I have found similar things when dealing with binary functions too. It’s the 2-3 liners that trip the model up!
That’s a wrap! Over and out.