
🎩 Top 5 Security and AI Reads - Week #18
AI red teaming automation wins, reproducible vulnerability containers, attacker control-based bug prioritisation, benchmark gaming exposed, and new binary vuln dataset.
Welcome to the eighteenth (!!) instalment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. We're kicking off with a fascinating exploration of automation's advantages in AI red teaming, revealing how a combination of automated tools and human expertise significantly boosts success rates in identifying vulnerabilities. Next, we examine ARVO, an impressive atlas of reproducible vulnerabilities for open-source software that provides ready-to-use Docker containers for pre-patched and post-patched code testing. We then delve into groundbreaking research on attacker control and bug prioritisation that introduces the innovative "Shrink and Split" approach to quantitatively assess vulnerability severity based on attacker input control. Following that, we explore "The Leaderboard Illusion" which exposes how benchmark access can lead to unreliable performance measures and suggests concrete improvements for fairer evaluation systems. We wrap up with BinPool, a valuable new dataset containing 603 unique CVEs across 89 CWEs from 162 Debian packages, addressing the long-standing gap in binary-level vulnerability datasets and offering promising resources for future security research.

This weeks commentary is a touch shorter than usual this week due to picking up another illness from the land of pestilence (my children’s nursery!)
Read #1 - The Automation Advantage in AI Red Teaming
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for folks who are interested in AI red teaming and how automation may already be coming for your job!
Commentary: I enjoyed this paper a lot. The paper uses data derived from Dreadnode’s Crucible platform to understand the benefits of automation when conducting AI red teaming. The main conclusion is that it helps a lot with a significantly higher success % as opposed to manual meatspace only. The most compelling conclusion is that a combination of automated and meat space may be the way forward, which I strongly agree with!
Another part of this paper that I really enjoyed was sections 8.2 For Defensive Measures and 8.3 Future Research Directions. These can be used as a starting point for researchers interested in the area but unsure where to start. The idea around creating detection systems for automated testing patterns sounds rad and can most certainly leverage some of the grand work associated with API and network security.
Read #2 - ARVO: Atlas of Reproducible Vulnerabilities for Open Source Software
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a great read for two groups of folks. Those who are interested in making high-quality research datasets and those who CBA making high-quality research datasets and instead want to get straight to the problem!
Commentary: I’ll preface this one with saying – I am so happy I didn’t have to do this personally, but hot damn is it awesome someone did! The authors of this paper have created a dataset of vulnerabilities in open source software using OSS-Fuzz as the source, but it gets so much better. Not only does it include the code down to commit level before and after the patch, but the authors only include vulnerabilities that can be recompiled. Each vulnerability included comes with its own set of Docker containers which enable you to compile the vulnerability pre- and post-patch as well as, I think, run the test crashing test case. And the cherry on top is that the entire thing is open source already or is planned to be!
Read #3 - Attacker Control and Bug Prioritization
💾: Zenodo 📜: arxiv 🏡: USENIX Security 2025
This is a grand read for folks that are interested in the cutting-edge approaches for binary-level vulnerability prioritisation not using LLMs. It’s the first paper I have read on the topic for a while that I didn’t think was a bit 💩.
Commentary: I really like the framing of this paper. It comes at the problem from the perspective of “With all these Gucci bug-finding techniques, how are we going to prioritise fixing them?” It does this by focusing on the level of control an attacker could have over the inputs that trigger the vulnerability and coming up with this notion of domains of control. They come up with a quantitative approach called Shrink and Split, which is calculated from path constraints created via symbolic execution. They then go on to compare this against taint-based measures as well as simple quantitative/qualitative measures and find the approach is much more effective.
The implementation itself seems to be within the Zenodo repo linked, and the USENIX folks seem to have been able to reproduce everything end-to-end, which is pretty cool. I am going to have a go myself, hopefully! It is only focused on Noddy memory corruption vulns, though (as usual!).
Read #4 - The Leaderboard Illusion
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for folks interested in how benchmark/leaderboard access can give unreliable measures of performance, as well as folks interested in getting some insight into how to run one of these leaderboards fairly.
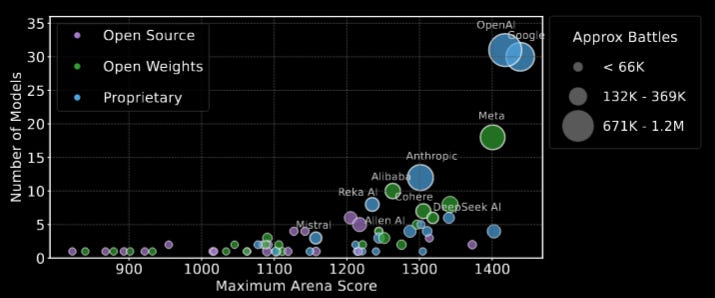
Commentary: This paper turns the half-baked and tongue-in-cheek commentary from a fair few folks saying there is benchmark cooking going on and actually proves that there is. The focus of the paper is on Chat Bot Arena, a crowdsourcing platform whereby users vote for which response they prefer between two model outputs. There are a few blind spots in this paper, but the one that really stuck out for me was that the authors found that model providers are able to submit multiple models for testing but then retract the crap ones. This feels like something akin to hill climbing but for the leaderboard. The paper is definitely throwing a few stones but does the hard work to suggest a range of sensible changes, such as prohibiting score retraction, changing the sampling method for models (pitting diverse models against each other for folks to score rather than biasing the better-known models) and generally increasing transparency of the whole process.
Read #5 - BinPool: A Dataset of Vulnerabilities for Binary Security Analysis
💾: GitHub 📜: arxiv 🏡: Pre-Print
This is another dataset paper which will be a grand read for folks wanting to get stuck into ML for vulnerabilities in binaries (maybe use bin2ml to process it?).
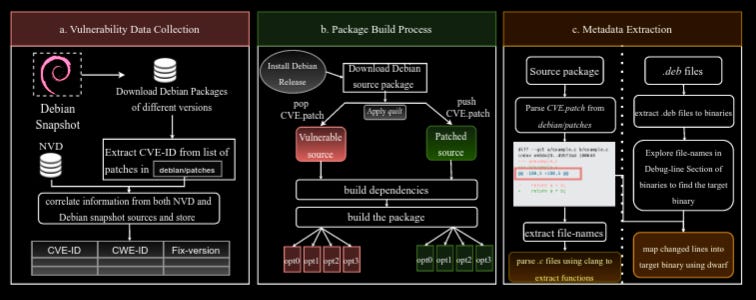
Commentary: It is great to see more binary vulnerability datasets being released. Source code has a few amazing datasets, but binary-level vulnerability datasets have been lacking for a while now. This dataset is a bit different from the one introduced by read #2, as it includes much less metadata, but the authors have released the entire generation process alongside the data itself. The dataset itself contains 603 unique CVEs across 89 CWEs from 162 Debian packages. Given its size, I think this will start being used as a held-out test set for vulnerability detection and search. I know I will be for my PhD!
That’s a wrap! Over and out.