
🎩 Top 5 Security and AI Reads - Week #22
LLM binary vulnerability detection, AI evaluation ecosystems, adversarial maritime defences, red-teaming scaling laws, and collaborative patching with smaller models.
Welcome to the twenty-second instalment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. We're kicking off with a compelling argument for moving beyond traditional benchmarking to better understand AI's real-world societal impacts through more comprehensive evaluation ecosystems. Next, we dive into an exciting agentic approach that leverages LLMs to detect vulnerabilities in stripped binaries, combining decompilation tools with multi-stage reasoning to achieve impressive results. We then explore innovative adversarial defence strategies in maritime autonomous systems, featuring a fascinating multi-sensor dataset and a novel confidence calibration technique. Following that, we examine groundbreaking research on capability-based scaling laws for LLM red-teaming, revealing how stronger models become better attackers and why social science capabilities matter more than STEM knowledge for attack success. We wrap up with a refreshing take on collaborative software patching that demonstrates how smaller, fine-tuned models can achieve near state-of-the-art performance at a fraction of the computational cost.

A note on the images - I ask Claude to generate me a Stable Diffusion prompt using the titles of the 5 reads and then use the FLUX.1 [dev] on HuggingFace to generate it.
Read #1 - Reality Check: A New Evaluation Ecosystem Is Necessary to Understand AI's Real World Effects
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for folks who are interested in how evaluations can be improved to go past just snapshot-in-time performance and will feel familiar to social science/socio-technical cyber folks. It’s the cyber argument all over again!
Commentary: This paper is good, but be prepared that if you do read it, it reads as 2-3 separate papers. The main argument throughout is that current evaluation strategies, namely benchmarking, do not capture the interplay between AI systems and humans as well as second- and third-order effects. I think this is true, and as AI systems start to be deployed more broadly, we need to understand what the effects are in meat space!
Read #2 - VulBinLLM: LLM-powered Vulnerability Detection for Stripped Binaries
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for folks interested in LLM-powered/agentic approaches for vulnerability detection in binaries!
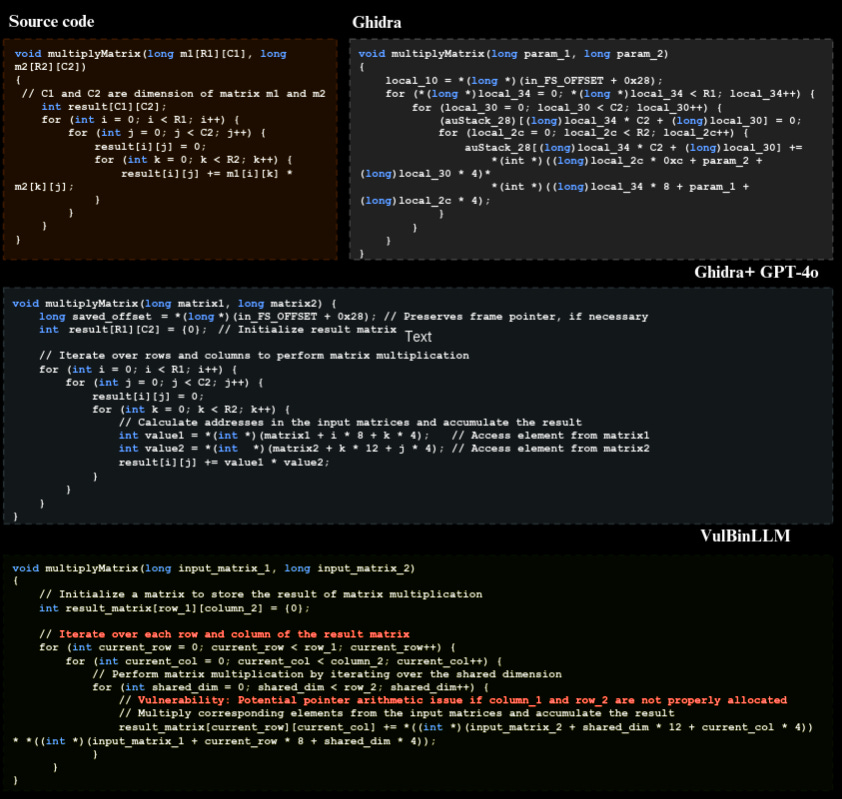
Commentary: I got very excited about this paper when I came across it! This paper presents an agentic system that takes in compiled binaries and spits out vulnerabilities. It uses Ghidra/Retdec to decompile the binaries into pseudo-C before then using a multi-stage LLM process to refine this decompilation, reason about it and then report results. It feels very similar to other papers that refine/clean up decompilation using LLMs but has gone a step further with not only fixing up things like variable names but also adding in comments to describe functionality. I think this makes a lot of sense!
The biggest weakness of this paper, however, is that the evaluation dataset is the Juliet C/C++ vulnerability dataset, which is now basically from the Jurassic era. It would have been so cool to see a real case study at the end of the paper on some real bugs. Nevertheless, the approach shapes up nicely against LATTE (another LLM-powered vuln thing) and across the board seems to have more true positives with fewer false positives, which is good! There are some odd numbers going on in Table 3 within the paper with the TP/TN/FN/FP adding up to significantly more than the number of reported test cases for a CWE, but we’ll chalk this up to an easy-to-fix mistake!
Read #3 - Preventing Adversarial AI Attacks Against Autonomous Situational Awareness: A Maritime Case Study
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand paper for folks who care about adversarial attacks in real-world, physical scenarios as well as folks interested in making novel/cool datasets.

Commentary: There are a couple of interesting things in this paper. The first and something the authors could probably write another paper about is the data generation procedure for this work. The data was collected from a real Uncrewed Surface Vessel (USV) and covers a variety of scenarios as well as data sources – radar screen recordings, 4K optical camera recordings, navigational charts and AIS data. This is a very interesting multi-sensor dataset, and some insights into the challenges of collecting and processing such data would be a fantastic paper!
The second is the verification/metricd, which combines several different model outputs to almost check if one or several contradict each other. This is then fused into a single metric which is used to calibrate overall system confidence. This feels like a very interesting approach and is something I personally had not seen done well before this paper. I imagine there are several use cases within old-money cyber for this sort of thing (like network, authentication and host logging?).
Read #4 - Capability-Based Scaling Laws for LLM Red-Teaming
💾: GitHub 📜: arxiv 🏡: Pre-Print
This paper is a banger and should be a must-read for folks interested in evaluating, researching and safeguarding against jailbreaks.

Commentary: I went on a bit of a trip with this paper and went from “This is a great paper” to “This is an iffy paper” to “This is a great paper”. The primary bit of my confusion here was how this paper uses an LLM judge. I am most familiar with using LLM judges in defensive contexts whereby you are using them to spot bad inputs and then flag those. Given this starting point, the paper describes using LLM judges to evaluate the attacker's input (i.e., the attack prompt) given some context and the response from the target model (if an attack had already been launched unsuccessfully). I was like “That is cheating” and then caught myself realising that why would an attacker not use a judge to filter out the bad attacks before launching them. This is akin to running an exploit against a local and non-internet-connected system that is similar to the thing you want to attack in old money.
After overcoming this inside my head, the results are pretty damn compelling. Rather than repeating them verbatim, here is the summary from the authors:
Stronger Models are Better Attackers. Attacker success, averaged over targets, rises almost linearly with general capability (ρ > 0.84; see Sec. 4). This underscores the need to benchmark models’ red-teaming capabilities (as opposed to defensive capabilities) before release.
A Capability-Based Red-Teaming Scaling Law. Attack success rates (ASRs) declines predictably as the capability gap between attackers and targets increases and can be accurately modeled as a sigmoid function (see Sec. 5). This finding suggests that while human red-teamers will become less effective against advanced models, more capable open-source models will put existing LLM systems at risk.
Social-Science Capabilities are Stronger ASR Predictors than STEM Knowledge. Model capabilities related to social sciences and psychology are more strongly correlated with attacker success rates than STEM capabilities (Sec. 6). This finding highlights the need to measure and control models’ persuasive and manipulative capabilities.
The most interesting thing for me, which is not directly capture in the above summary, is that the authors found that the power of the attacking model drives attack success rate not the power of the LLM judges. This means that using a closed-source model such as OpenAI/Claude is not really needed. And the last thing I found cool was the unlocking method used by the authors to remove safety fine-tuning. This allowed them to use safety-tuned models within this evaluation.
Read #5 - Co-PatcheR: Collaborative Software Patching with Component(s)-specific Small Reasoning Models
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for folks interested in agentic approaches to source code vulnerability patching but also for folks that are researching or want to use smaller models for security tasks.

Commentary: I found this paper such a refreshing read. Rather than leveraging a closed-source or huge open-source model and building a scaffold around it, the authors of this paper have approached this problem with “Can we get somewhere near to SOTA with much less”?" They have taken reasoning data generated by Claude from a refined patch dataset before then fine-tuning several Qwen-2.5-Coder-14B models. The results in Table 1 of the paper speak for themselves, with the proposed approach, PatchPilot, being the strongest open-source model and only 14% off Claude 3.7 OpenHands. There is some oddness in this paper, though. It would have been nice to see other open-source models evaluated in the same agent scaffold as the authors' fine-tuned models to isolate the effect the data refinement/distillation had versus the agentic setup
That’s a wrap! Over and out.