
🎩 Top 5 Security and AI Reads - Week #39
Adversarial deepfake defence, production malware detection attacks, GPU-based ML authentication, multi-agent vulnerability detection, and training data scaling for adversarial robustness
Welcome to the thirty-ninth and last Stats and Bytes weekly newsletter. It has been a wonderful experience regularly writing this newsletter for nearly 300 weekly readers for 10 months. I have learnt a lot along the way and hope it’s been a useful resource regardless of whether you are a novice, researcher or practitioner. Unfortunately though, the time required to write this newsletter has been slowly but surely been bleeding into my weekends and impacting on time with my family. When starting writing this newsletter, I grossly underestimated the amount of time it takes to find, read, write-up and then edit 5 papers into summaries that are somewhat useful. It’s been a good run and thank you for all of the feedback and encouragement along the way. All previous newsletters are open for anyone to access and the generous folks who were on paid subscriptions, I have cancelled them so no more funds will be taken!
Anyhow, let’s jump into the five papers covered this week. We’re kicking off with a look at how adversarial perturbations can be weaponised for good—using carefully crafted noise to sabotage deepfake attacks. Next, we have a gander at a real-world case study of attacking and defending Google’s Gmail file routing service and how Magika is used within this system, revealing how a single round of AES encryption became an unexpected defence against evasion attacks. We then jump into innovative research on authenticating ML models and datasets on-the-fly using GPU architectures. Following that, we explore a multi-agent approach to vulnerability detection that helpfully includes actual prompt templates and has a range of different agent types. We wrap up with a compelling investigation into whether simply throwing more training data at vision models improves adversarial robustness—spoiler: it helps, but other factors are more important.

A note on the images - I ask Claude to generate me a Stable Diffusion prompt using the titles of the 5 reads and then use the FLUX.1 [dev] on HuggingFace to generate it.
Read #1 - Towards Imperceptible Adversarial Defense: A Gradient-Driven Shield against Facial Manipulations
💾: N/A 📜: arivx 🏡: Blog Post
This should be a good read for folks interested in how adversarial attacks/perturbations can be used for defensive purposes.
Commentary: This paper caught my eye because it is using adversarial perturbations as a defence against deepfake attacks – attacking the attacker! I like the idea of adding your own perturbations in to push deepfake models to generate some very strange stuff. The majority of the paper is focused on how to make these perturbations less obvious so when you are attacking your own images, you are doing so in a way that does not affect utility (i.e., how the image/video looks to a normal user). The paper has several great figures that show the impact of the perturbations on deepfake models, and it looks pretty effective. The biggest challenge with a lot of these approaches is how to do this in real time and efficiently, especially for video.
Read #2 - Evaluating the Robustness of a Production Malware Detection System to Transferable Adversarial Attacks
💾: N/A 📜: arxiv 🏡: Pre-Print
This will be a great read for folks who are into developing/researching malware detection algorithms but also securing large-scale production deployments of ML.
Commentary: I found this paper really interesting. It details the end-to-end process of assessing, attacking and then proposing a defence for a production model. In this case, the Magika model is used by Google to scan files in Gmail. The Magika model is used to classify input files into categories. The predicted category is then used to route the file to the relevant malware scanner (PDFs go to the PDF scanner, Windows executables go to the Windows executable scanner…). This paper focuses on getting a misclassification out of Magika so malware attached to an email gets routed to a scanner that won’t be able to spot it and subsequently gets to the target user.
There are a fair few cool bits in this paper, such as a section on format-preserving attacks, which is rarely covered in this literature, but the thing I thought was the most interesting is the defence that they actually integrated into the Gmail classifier – a single round of AES encryption. The authors add a single round of AES encryption to the data preprocessing, retrain the model on this new preprocessed data and find that the transferability attack success rate is greatly reduced. Is pre-processing obfuscation now a legitimate strategy? What a time to be alive.
Read #3 - Sentry: Authenticating Machine Learning Artifacts on the Fly
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a good read for folks interested in authentication and how GPUs can be used to verify the authenticity of ML artefacts.
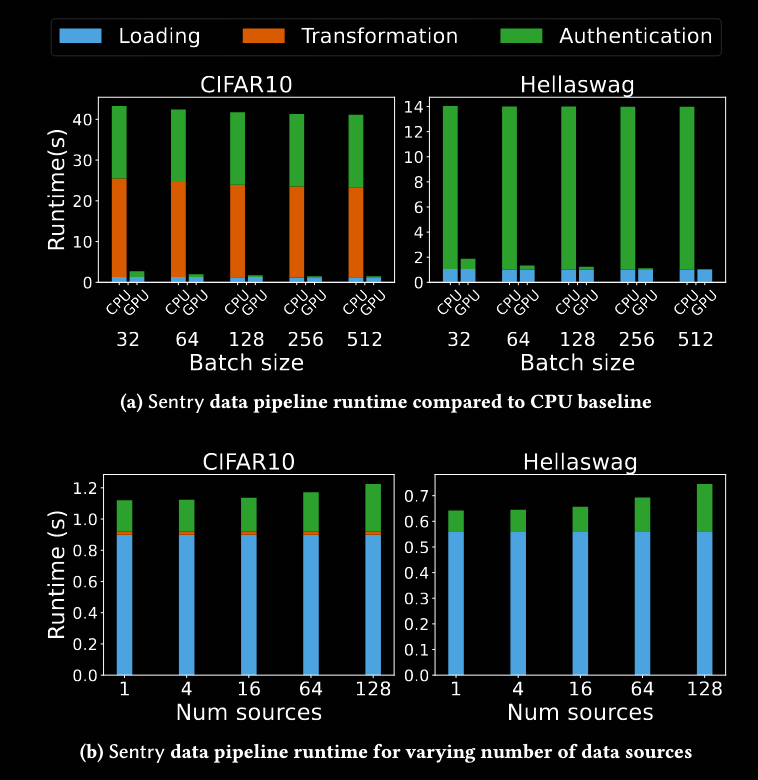
Commentary: I am unable to comment on the technical quality of this paper, as it uses a fair few cryptographic bits and pieces I am not deeply familiar with, but the premise was interesting enough for me to include. The general gist of this paper is how to verify that an ML model or training dataset is authentic, leveraging GPU architectures. The biggest challenge, which is highlighted in the paper, is how to do this efficiently so the authentication doesn’t take ages. Figure 9 (below) shows the overhead – it is not too bad on GPU, but a 15% increase in inference time can quickly add up. That being said, for high-assurance use cases, it could be justified.
Read #4 - MAVUL: Multi-Agent Vulnerability Detection via Contextual Reasoning and Interactive Refinement
💾: GitHub 📜: arxiv 🏡: Pre-Print
This should be a good read for folks who are interested in multi-agent implementations and, obviously, vulnerability detection!
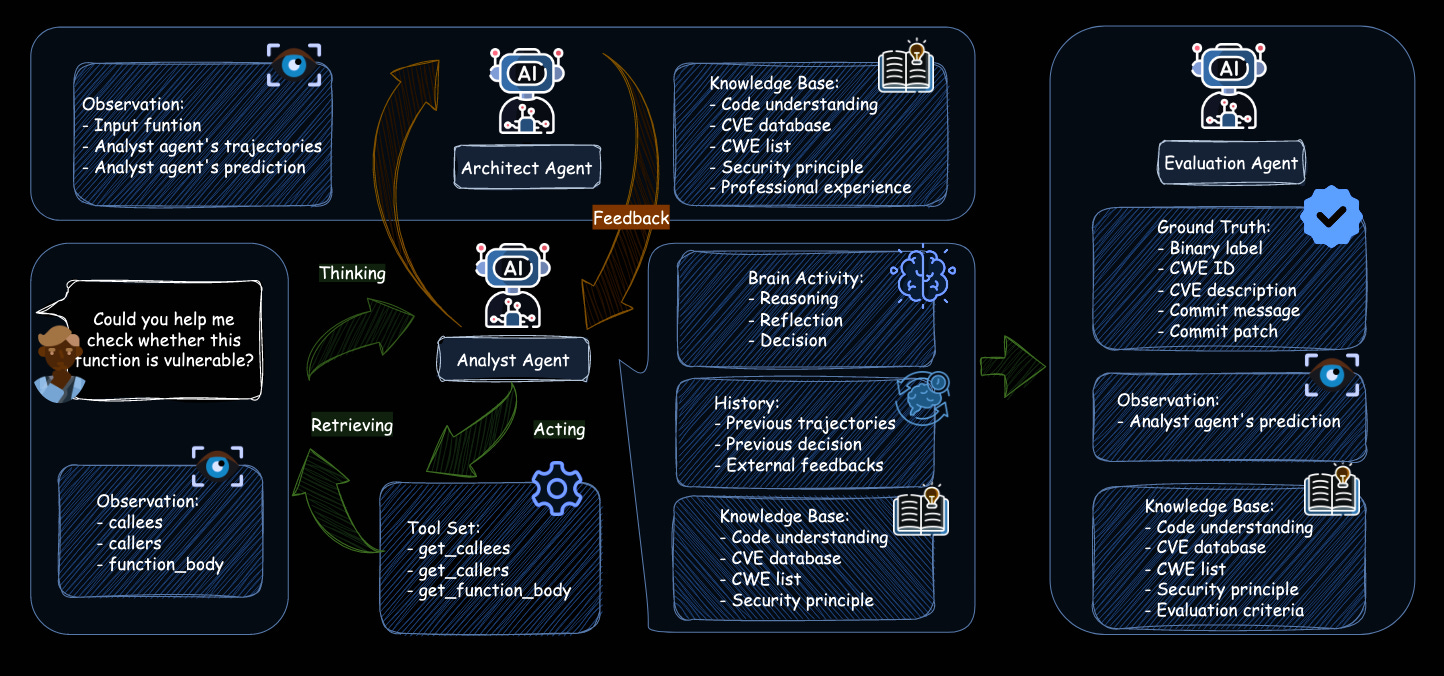
Commentary: Aside from the approach beating everything it’s compared to (obviously) and the somewhat iffy custom dataset that’s pretty small, I really appreciated the inclusion of inline prompt templates for the different agents in this multi-agent setup. I wish more papers did this! Digging a bit further into the results, the dataset seems to be hella hard, with the strongest approach (the one proposed) only achieving a 17.5% P-C score (predicting pre-patch was vuln and post-patch was not vuln). I have added this to my “Email if cited list”, and I am hoping to dig into the code in more detail.
Read #5 - The Impact of Scaling Training Data on Adversarial Robustness
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for folks interested in more theoretical or general research papers.
Commentary: This caught my eye because it’s something we’ve known for a while in terms of performance – more data usually results in better performance. This paper conducts similar research but for adversarial robustness. It is worth being very clear – this research is for vision models, not language ones, and the title is a little bit of a cliffhanger. The authors find that training data scaling does have an effect, but data quality, architecture choice and training objective play a more important role. I think we kind of already knew that by applying the old adage – shit in, shit out. That being said, this paper does cover models ranging from 1.2M to 22B, so we definitely know now.
That’s a wrap! Over and out (for good this time! 😭)