
🎩 Top 5 Security and AI Reads - Week #17
LLM-powered vulnerability triage, automated malware rule generation, LLM censorship steering, vulnerability detection evaluation, and AI governance language problems.
Welcome to the seventeenth instalment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. We're kicking off with a fascinating exploration of how LLMs can augment static analysis tools to reduce false positives in vulnerability detection, achieving impressive results on the Android Linux kernel. Next, we examine an innovative approach to automatically generating malware detection rules across multiple programming languages using LLMs, dramatically improving accuracy over stock rules. We then delve into groundbreaking research on LLM activation patching that reveals how to steer model behaviour between refusal and compliance, raising important questions about AI safety and censorship. Following that, we explore a comprehensive review of LLM-based vulnerability detection methods, critically analysing their effectiveness across various open-source libraries. We wrap up with a thought-provoking discussion on how the language we use in cybersecurity and AI governance shapes our understanding and actions, challenging common metaphors and proposing more human-centred terminology.

A note on the images - I ask Claude to generate me a Stable Diffusion prompt using the titles of the 5 reads and then use the Stable Diffusion Large space on HugginFace to generate it.
Read #1 - The Hitchhiker's Guide to Program Analysis, Part II: Deep Thoughts by LLMs
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for folks interesting in source code bug finding and in particular how static analysis tools and LLMs can work together for glorious bug finding.
Commentary: I am a big fan of this paper. The primary premise is using an LLM to reduce the false positive rate of static analysis tools. The reason this is useful is that static analysis tools usually use heuristics/rules to detect vulnerabilities, and this results in a very high false positive rate (because most of the time the preconditions in the source code make it not a bug or it’s just a common pattern).
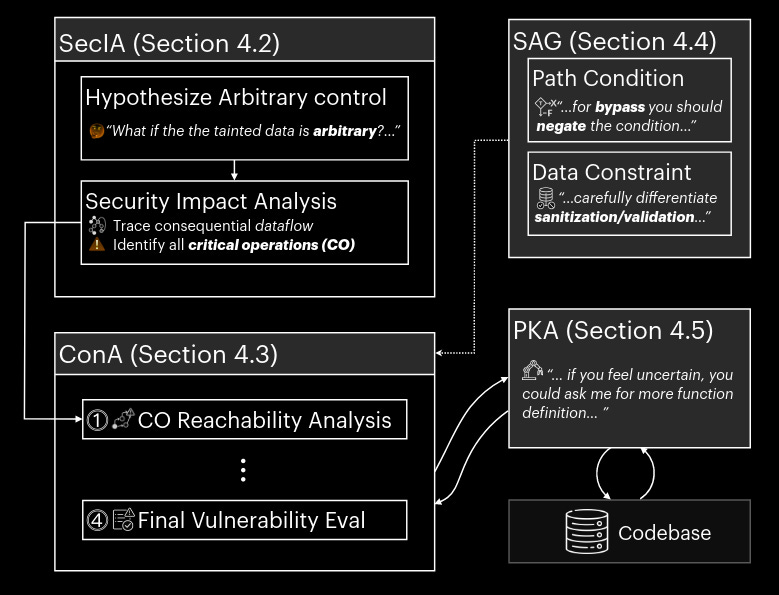
Now, you might be thinking, “Pah, it must be being run on something rubbish like a load of small binaries…” Well, this is being run on the Android Linux kernel – a monster of a piece of software. The approach itself takes in the raw detection’s from a static analysis tool (in this case, Suture and a bundle of CodeQL rules) before then putting the detection’s through BugLens, a tool with 4 main components.
The components of BugLens are:
Security Impact Assessor – This bit asks the question, “If the tainted data that triggered this static analyser alert was wholly attack controlled, what are the potential security impacts?” before then asking, “Does the tainted value potentially lead to a security vulnerability?” It took me a while to stew on why this is useful, but I came to the conclusion that it is a cool way to fill up the context of the LLM with relevant vulnerability information before then asking the juicy question.
Constraint Assessor – This bit starts with the question of “What are the reachability and constraints on the sources and sinks?” and then asks the model to summarise this information before then evaluating which of the static analysis alerts are true vulnerabilities.
Structured Analysis Guidance – This is essentially prompt engineering whereby the authors have leveraged knowledge of program analysis to craft prompts with good examples within them to drive the LLM's output.
LLM Agent for Codebase Information – This bit is an agent that can interact with the source code of the project under test. It’s a bit unclear at which stage this can be used, but it can be viewed as a tool.
The thing I found fascinating too was this bit:
BugLens is implemented with approximately 7k tokens (30k characters) in prompts (detailed in §B) and 2k lines of Python code that manages API requests and code base querying functionality.
We are now in the territory where, for security research, we are writing more prompt templates than actual code – bonkers.
The results of this paper speak for themselves – Suture as is identifies 24 TP with a total of 227 FP’s. With the entire system described above, the authors manage to get this to 24 TP’s but only 9 FP’s. I think this is wild, and I look forward to seeing where this research ends up.
Read #2 - Automatically Generating Rules of Malicious Software Packages via Large Language Model
💾: N/A 📜: arxiv 🏡: Pre-Print
This is another grand read which is in a similar space as the above but instead uses the LLM to generate the rules to detect bad stuff in different languages (Python/JavaScript/Go).
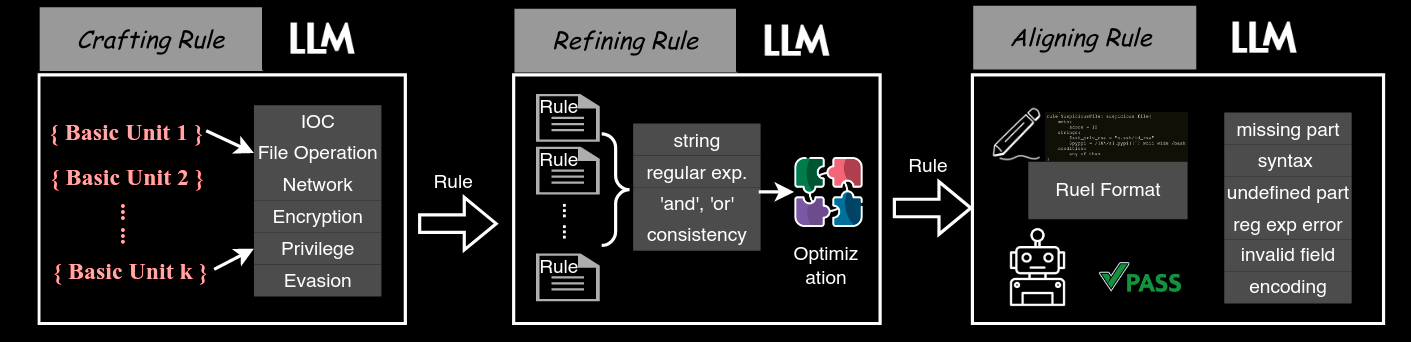
Commentary: This paper takes a different approach than the paper above and instead focuses on generating better rules for static analysis tools to use. They use YARA and Semgrep (which is a very similar tool to CodeQL used in the previous paper). The approach is a 3-stage process with the following stages:
Creating initial rules – This works by taking features of the input code or metadata about the packages (the dataset the paper uses is packaged software like Python packages from PyPI) and then providing these features to the LLM to create a valid rule.
Refining rules – This works by essentially merging rules into one big rule using things like all of them and any of them keywords or plain old regex. This is called rule optimisation by the authors. The authors also detail a process of self-reflection whereby the LLM is asked to audit the previously generated rules.
Aligning Rules – This works by doing a loop of compiling the rules to check if they are valid. If they are not and we get an error message, provide it back to the LLM and ask it to fix it. Otherwise, we are golden!
The evaluation of this approach is a tad dodgy for a couple of reasons. Firstly, the dataset is skewed towards bad stuff, with 3.2K bad packages and 500 good ones. I can imagine as the number of benign packages increases, the false positive rate will grow loads. And secondly, the authors use the stock rules provided by YARA and Semgrep, which are unlikely to contain any of the malicious packages used within the dataset. It would have been better to get a human (or several) with domain expertise to create some rules for a subset and do the eval on that. Anyways, the results are pretty impressive, as you can see below:
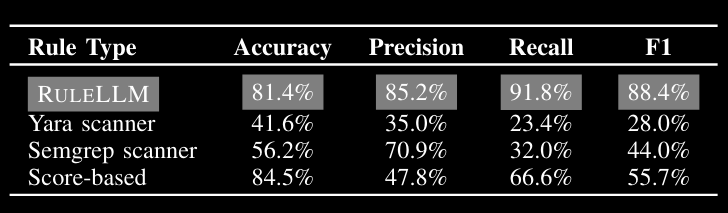
I did think that it could be cool to see an approach that integrates this approach with the approach above. It would be very interesting if you could encode the analysis of paper #1 after it has completed in a collection of rules using this approach. Maybe something for someone to explore?
Read #3 - Steering the CensorShip: Uncovering Representation Vectors for LLM "Thought" Control
💾: GitHub 📜: arxiv 🏡: Pre-Print (Under-Review)
This is a grand read for folks interested in the mechanistic interp area as well as how it can be used to assess censorship risks when you have access to the model itself.

Commentary: I enjoyed this paper a lot. It’s a pretty simple approach but applied to an interesting area. The approach uses activation patching, which means taking the activations of a layer and adding/subtracting a vector of the same dimension to cause some effect.
The first interesting bit of this paper is how they find the vector to patch. They do this by looking at the activations and doing string matching on the outputs given an input. To make this a bit more concrete (and missing a few of the details), the paper gets this vector by providing a model with a collection of prompts that are known to cause refusal. Imagine input prompts like “How do I make a bomb?” and outputs like “I am sorry, I am unable to do this…". A layer within the network is chosen, and the activations are analysed to identify which of the neurones within the layer are responsible for the refusal (i.e., have the biggest values). Usually, these values can be used as is and then subtracted (i.e., reducing the value of a given neurone) to remove the refusal. The novelty in this paper (I think) is that they do this calculation across tokens to get a sort of aggregate result.
The second interesting bit is how effective this approach is. For the benchmarks used across basically all models that have been safety tuned, the authors manage to reduce the refusal rates to under 10%, with most being 90%+ prior to subtraction-based activation patching (removing censorship/refusal). Interesting, the authors also apply the same vector but as addition-based activation patching (adding more censorship/refusal). The results from these experiments show the authors can bump the refusal rate up to 100% most of the time.
There is also an interesting experiment around the thought suppression concept, but this post is getting a tad long, so I will leave that to you, the reader, to dig into!
Read #4 - Everything You Wanted to Know About LLM-based Vulnerability Detection But Were Afraid to Ask
💾: Anon4Science (Anon GitHub) 📜: arxiv 🏡: Pre-Print
This is linked to read #1 and #2 but is more of a review/critique of the whole area as well as proposing a solution. The vulns in this paper are mostly C open-source libraries (like FFmpeg).
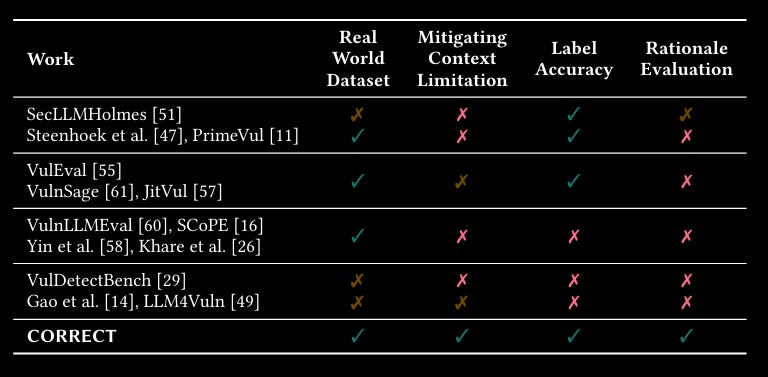
Commentary: I came across this paper towards the tail end of this week, so I have not had enough time to really dig into it, but from what I have read, it seems like a great paper. It evaluates a fair number of open weight models to understand their performance when detecting vulnerabilities. It uses CWEs as the categorisation for the vulnerabilities but confusingly uses the top-level categorisations rather than the more granular ones (for example, CWE-664 – Improper Resource Control, which is 56.2% of the dataset, is discouraged to be used!). This makes it a bit difficult to understand the types of vulns being analysed, but other than that, the methodology seems sound. It’s been added to the “Read in detail” list.
Read #5 - Naming is framing: How cybersecurity's language problems are repeating in AI governance
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a non-technical read but worth it for everyone interested in what AI and security mean. It focuses on how language drives understanding and actions.
Commentary: This is a cracker to end on and one that might be a bit controversial. This paper argues that the language used is crucial to drive AI governance, but I actually think it applies much more broadly to policy as well as research. It starts by digging into language issues in cybersecurity before suggesting a series of alternative terms for AI-related stuff with a focus on challenging metaphors.
The author targets the terms alignment, trustworthy AI, black box, hallucination, control problem, autonomous system and intelligent agents. And I have to say, I agree with most of what the author argues. The principle of keeping the user/human at the centre of all this stuff resonates with me, as well as keeping the terms objective and non-adversarial, which is key. I am interested to hear what folks think after reading this and stewing. Drop me a message if you want to chat.
That’s a wrap! Over and out.