
🎩 Top 5 Security and AI Reads - Week #23
Malware dataset evolution, privacy-preserving search obfuscation, automated exploit generation, MLOps security survey, and vulnerability dataset quality assessment
Welcome to the twenty-third instalment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. We're diving straight into the refreshed EMBER2024 dataset, which has been upgraded to include a comprehensive collection of malware samples across multiple platforms and file formats, complete with Rust-powered tooling for future updates. Next, we explore a snazzy privacy preservation technique that uses random multilingual search queries to obfuscate user interest profiles, effectively throwing off tracking algorithms by adding noise. We then examine a sophisticated LLM-powered system that combines static analysis, dynamic testing, and iterative refinement to automatically generate proof-of-concept exploits for npm package vulnerabilities, achieving notable success rates on both established and new datasets. Following that, we have a brief gander at a comprehensive survey of MLOps security that maps attacks to the MITRE ATLAS framework while reassuringly finding that many traditional security practices remain effective in ML environments. We conclude with a grand paper on vulnerability dataset quality, where researchers challenge the "clean" nature of existing datasets and propose multi-agent LLM systems to filter out undecidable patches.

A note on the images - I ask Claude to generate me a Stable Diffusion prompt using the titles of the 5 reads and then use the FLUX.1 [dev] on HuggingFace to generate it.
Read #1 - EMBER2024 -- A Benchmark Dataset for Holistic Evaluation of Malware Classifiers
💾: Data + Loading (GitHub) | Data Gen (GitHub) 📜: arxiv 🏡: Pre-Print
This is a grand read for folks interested in malware detection. One of the OG malware datasets has just got a facelift!
Commentary: There is not much to say about this other than it’s awesome. The paper goes into detail around the specifics of how the data was collected and curated. What is very cool is the paper includes both the data/loading code as well as a CLI tool (written in Rust +1 from me!) to update the dataset in the future. What is also very cool is this dataset covers PE files of different bitness, .NET files, APKs, ELFs and PDFs. I am looking forward to tracking the citations this gets!
Read #2 - Hiding in Plain Sight: Query Obfuscation via Random Multilingual Searches
💾: Code (GitHub) 📜: arxiv 🏡: Pre-Print
This is a grand read for folks interested in privacy preservation when searching for stuff.
Commentary: I found this paper really interesting. I remember a fair while ago now a Chrome extension got a bit of coverage for conducting random web searches and accessing websites in the background whilst you browse. The aim of this was to make your traffic patterns look bonkers and throw off any downstream analytics. This is essentially the same idea but instead does it via sending random multilingual queries to throw off “user interest profiles”. The tool is open source, and the results presented in the paper suggest that the tool is effective, at least against the search engine they used.
This paper did get me wondering, though – is there a version of this but for LLM quer
Read #3 - PoCGen: Generating Proof-of-Concept Exploits for Vulnerabilities in Npm Packages
💾: Code + Data (FigShare) 📜: arxiv 🏡: Pre-Print
This is a grand read for folks interested in tracking the exploit generation capabilities of LLMs (albeit in an interpreted language!).
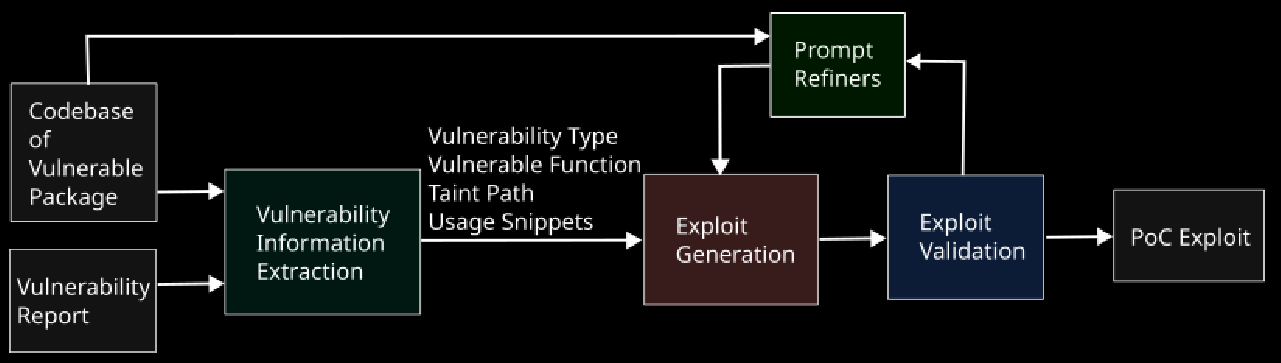
Commentary: This paper was a grand read. The authors propose an end-to-end process whereby they take the source code and write up a vulnerability and iteratively refine a PoC exploit for it. The key innovation in this paper is the use of static and dynamic analysis tools (such as CodeQL, Coverage Tracking and a Debugger) to help with the refinement.
This all combines together to get a 77% pass rate of an open-source dataset, SecBench.js (which may very well be in the LLM’s training data and only contains vulns to 2022). The authors also create their own dataset called CWEBench.js, which contains a range of vulns from 2013 to 2025 and excludes all of those present in SecBench.js. On this dataset, the approach gets 39%, which is much less scary but still impressive.
There is a fair bit of detail in the results section that I couldn’t dig into very much, but I think there is an interesting bit of analysis to do around whether the static analysis tooling (like CodeQL) supports all of the vuln classes equally. I have a sneaky suspicion that they probably don’t, and there may be a relationship between LLM capability, static/dynamic analysis coverage and POC exploit quality. Maybe something for someone to take forward?
Read #4 - Towards Secure MLOps: Surveying Attacks, Mitigation Strategies, and Research Challenges
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for anyone interested in all things security of MLOps systems/pipelines and is a great primer for pen-testing folks wanting to understand what might be different in an MLOps environment.
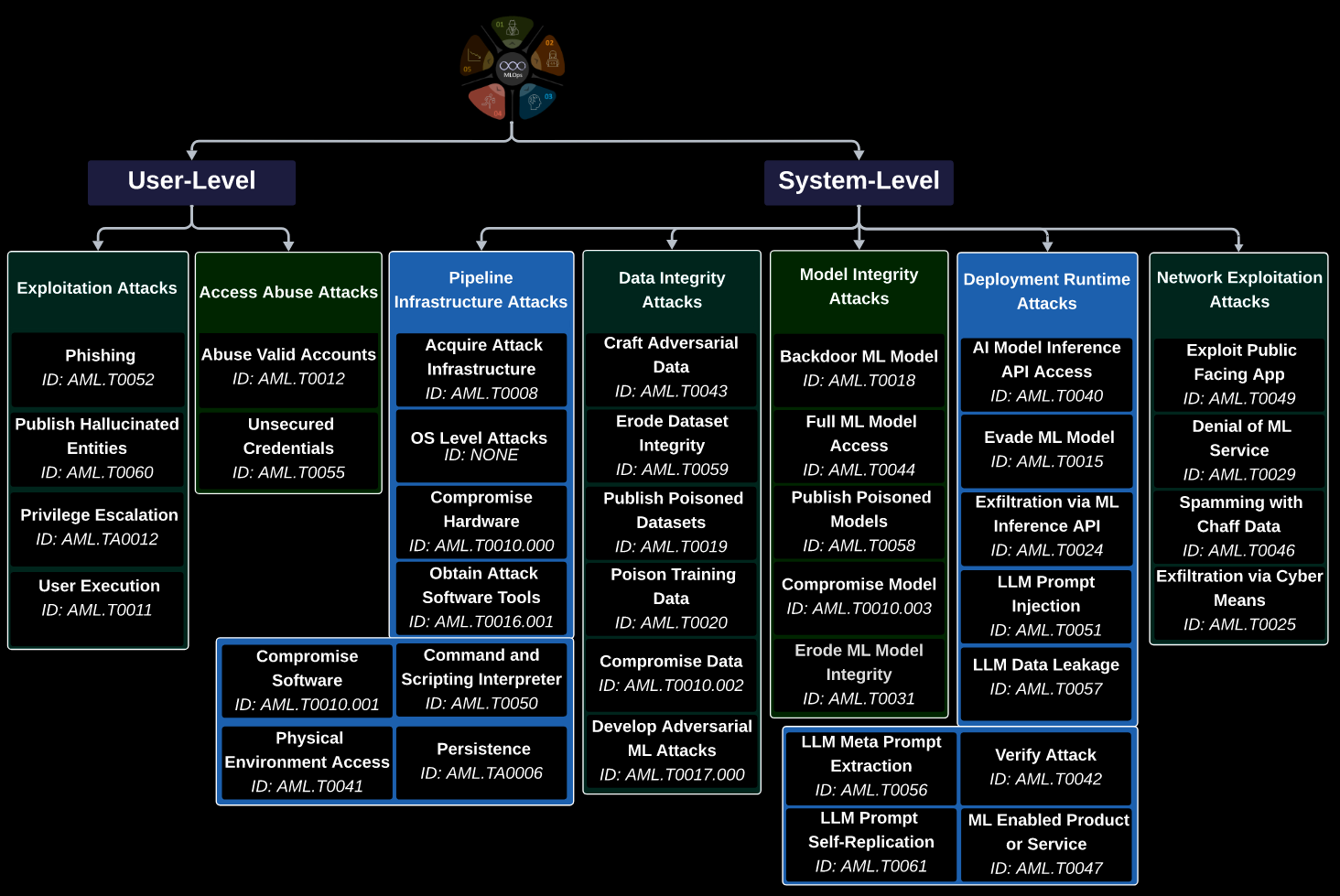
Commentary: This paper is packaged full of great stuff. It covers a huge range of different attacks and maps them to MITRE ATLAS (the AI security version of MITRE ATTACK). It then moves on to go through the mitigation options. I read the mitigations and was very happy to see a lot of them are traditional security best practices. The authors didn’t feel like they needed to reinvent any wheels. :D And the final section covers research challenges and recommendations. This section is a goldmine for anyone wanting to spin up some research in this area!
Read #5 - Mono: Is Your "Clean" Vulnerability Dataset Really Solvable? Exposing and Trapping Undecidable Patches and Beyond
💾: N/A 📜: arxiv 🏡: Pre-Print
This is an interesting read for folks who a) want to train/use vulnerability datasets and aren’t sure what the issues are with the open-source ones and b) folks interested in methods to clean up/enhance datasets.
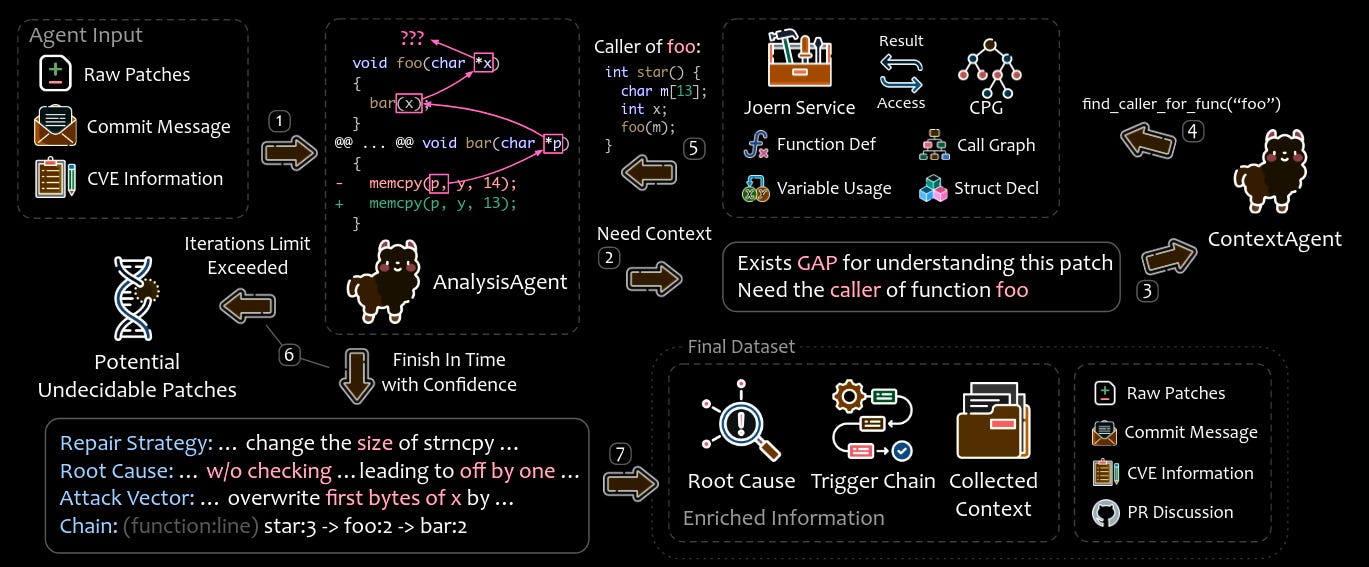
Commentary: This paper has two main parts. The first is focused on filtering patches. The general idea here is that, due to the automated approach used when creating large vuln datasets, some of the patches are likely benign and not actually fixing any security vulnerability. The authors add PR discussion content alongside the raw patch and commit message. I think this approach is good but definitely not foolproof. There is a lot of nuance here which is being passed off to an LLM without that much prior thought. I can’t think of any specific examples off the top of my head, but it is not unheard of for folks to patch security vulnerabilities with commit messages that look benign and little to no PR chatter! The next stage is a multi-agent LLM system which iteratively processes the vulnerability to identify the root cause and relevant metadata. The output of which is a yay or nay for if the vulnerability should be included in the final dataset.
Another key thing this paper pushes is the concept of “undecidable patches”. These are vulns that require extensive external context to make sense. The authors assume that if, after doing the iterative process above, the LLM is not confident there is a vulnerability, it does not get included. I personally am not 100% comfortable with this approach. It feels like it compounds the weaknesses in the static analysis tools with the weaknesses of the LLMs and then bakes this into the downstream dataset. I have this added to the “If cited, email me” list, and we’ll see where it ends up!
That’s a wrap! Over and out.