
🎩 Top 5 Security and AI Reads - Week #29
Rowhammer attacks on GPUs, space cybersecurity testbed frameworks, architectural backdoors in deep learning, attention-aware prompt injection attacks, and LLM cryptography capability benchmark
Welcome to the twenty-ninth instalment of the Stats and Bytes Top 5 Security and AI Reads weekly We're kicking off with a look at GPUHammer, an attack that brings the notorious RowHammer technique to GPU memories, demonstrating how attackers can break machine learning model performance through strategic bit-flips. Next, we examine an innovative fidelity framework for space cybersecurity test beds that provides a comprehensive approach to building realistic hardware-based security testing environments. We then jump into a thorough survey of architectural backdoors in deep learning systems, offering a detailed taxonomy of vulnerabilities that blend traditional cybersecurity threats with modern AI attack vectors. Following that, we explore an attention-aware prompt injection attack that cleverly circumvents recent fine-tuning-based prompt injection defences by leveraging architectural insights to optimise adversarial prompts. We wrap up with a benchmark evaluating large language models' cryptography capabilities, revealing the reassuring limitations of current AI systems when faced with real-world cryptographic challenges and proofs.

A note on the images - I ask Claude to generate me a Stable Diffusion prompt using the titles of the 5 reads and then use the FLUX.1 [dev] on HuggingFace to generate it.
Read #1 - GPUHammer: Rowhammer Attacks on GPU Memories are Practical
💾: GitHub 📜: arixv 🏡: USENIX 25
It’s hammer time! This should be a great read for folks interested in fault injection attacks and the brave new world of security folks whacking GPUs.
Commentary: This paper introduces a GPU variant of RowHammer, an attack that causes bit-flips within memory. The paper walks through a lot of the technical details, such as how memory on a GPU is structured, the unique challenges when trying to “hammer” GPU memory, and the method used to generate the primitives required for the attack.
The paper starts to get really juicy, though, when you get to section 8. This covers the end-to-end exploit against an Nvidia A6000 GPU. The models they target are AlexNet, VGG16, ResNet50, DenseNet161 and Inception V3, and they come up with 8 different bit-flip attacks. Long story short, most of the attacks turn OK models into awful ones (like 75% acc to 1%). This attack is also doable in a multi-tenant or GPU slice environment, making it a somewhat worrying development!
All is not lost, though! The authors of this paper relax a few things to get their attack to work, such as assuming a multi-tenant environment (i.e., several folks on the same GPU) and that the attacker has the ability to memory massage the whole GPU (which I think would not be the case in a multi-tenant environment!). They also have a very interesting section suggesting that these attacks are very GPU specific, with different GPUs seemingly having different resistances to these types of attacks.
Given the development and log tail on Rowhammer research, I imagine this is going to be built upon significantly, especially as they dropped the code too!
Read #2 - Space Cybersecurity Testbed: Fidelity Framework, Example Implementation, and Characterization
💾: N/A 📜: arxiv 🏡: SpaceSec 25
This paper is out of this world (harh harh harh) and should be a grand read for folks interested in doing space cyber stuff but don’t have access to the real hardware easily!
Commentary: This paper is obviously space-focused, but I think the framework they come up with can be generalised to basically any cybersecurity testbedthat uses real hardware. The figure below really does cover all the bases in my mind.
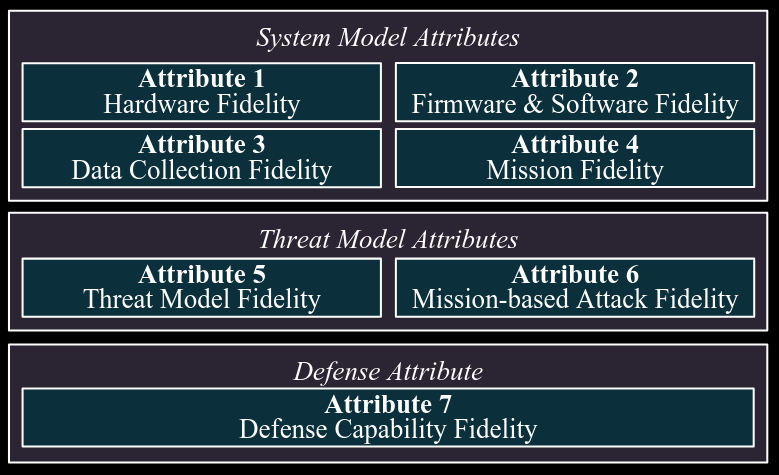
They use the above framework to create a physical test bed and then identify areas for improvement. I especially liked the section that went through the different threat modelling and attack scenario considerations. For folks designing physical test beds, I’d give this an in-depth read!
Read #3 - Architectural Backdoors in Deep Learning: A Survey of Vulnerabilities, Detection, and Defense
💾: N/A 📜: arxiv 🏡: Pre-Print (Under review at ACM Computing Surveys)
This is a grand read for folks who are interested in model security and attacks which blend old money cyber with the new world of AI systems.
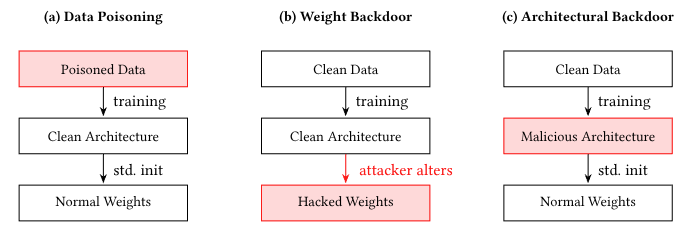
Commentary: Worth prefacing this commentary with saying this is a paper I co-authored with Victoria and Jodie within my group at Turing, so I might be a little biased! The paper itself has three main contributions. The first is an adapted 12-category taxonomy of architectural backdoors building upon previous work that dropped earlier in the year. This taxonomy contains 4 larger buckets: sub-network attacks, compiler-based backdoors, AutoML/NAS-based backdoors and hybrid attacks. I found the compiler-based backdoors and the hybrid categories the most interesting and feel like they’ll see the most showtime in the wild.
The paper's second contribution is a section on detection and mitigation strategies which covers a lot of ground and I hope will be useful to many researchers that are interested in creating mitigation! The strengths and weaknesses of popular approaches are analysed and suggestions made for why these arise. The paper then concludes with a section on open challenges and future research directions. There is a lot of runway in this area, and I hope this section gives interested researchers some ideas to get chipping away at this area!
Read #4 - May I have your Attention? Breaking Fine-Tuning based Prompt Injection Defenses using Architecture-Aware Attacks
💾: GitHub 📜: arxiv 🏡: Pre-Print
This is an interesting read for folks wanting to get into the nitty-gritty of optimising attacks for different targets, in this case making GCG better at going after recent security-focused fine-tuning methods.
Commentary: This paper was a good read, albeit it has the typical weaknesses of prompt injection research (marginal gains, very strong threat model, no consideration for defender mitigations). The work goes after two recent security-focused defensive approaches called StruQ and SecAlign. Both of these approaches work by using a method (adversarial training for StruQ and preference optimisation for SecAlign) to fine-tune the target model to use special tokens/delimiters to zero out or ignore bad inputs. The authors identify that this approach is pretty effective against start GCG attacks and formulate an extension to GCG called ASTRA (but also referred to as GCG++ in the paper).
ASTRA leverages knowledge about the architectural properties of the LLM to generate better prompt injection attacks. This is done by creating a new loss function. The key ingredients to this loss function are two things: a) the attention weights across each token within an input sequence b) a clipped “sensitivity” weight across each token in an input sequence. These two quantities are mashed together and used to optimise the GCG attack. The authors say this is a “warm start” for the GCG attack. I stewed on this for a bit and came to the conclusion that this information (attention weights and weight sensitivities) is giving the attack a good signal for inputs that trigger the learnt defences. The optimisation object then becomes minimisation of these two quantities, or in other words, do not trigger the defences!
The results show that the attack does do better than vanilla GCG, but I am not convinced by the threat model. It’s basically complete access to the model to instrument and get the required information out. I think the authors missed a trick by not trying to generate attacks on a model they had (like the base model of StruQ) and then used it on the model the pseudo-target had (like the actual StruQ). This would have been a much more realistic setup. The authors also say that their attack is 2x slower than GCG and GCG was snail-level speed to start with. :O
Read #5 - AICrypto: A Comprehensive Benchmark For Evaluating Cryptography Capabilities of Large Language Models
💾: Github.io 📜: arxiv 🏡: Pre-Print
This should be interesting to folks who wanted to keep track of LLM’s cyber/security related capabilities!
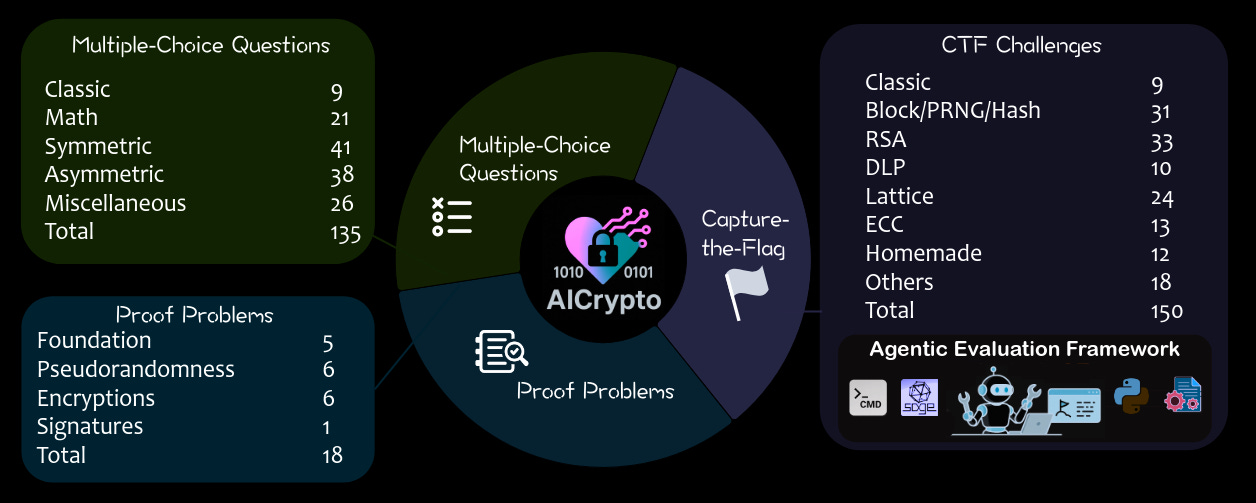
Commentary: I’ll preface this commentary by saying I am a complete crypto n00b, so regarding the cryptography aspects of this paper, I have very little to say other than “Looks good to me!” The benchmark itself looks OK. There are lots of issues with multiple-choice question benchmarks, but having it balanced out with CTF challenges and proof problems, I think, is fair.
The authors use the benchmark to evaluate 17 models (all the usual names!). Unsurprisingly, the LLMs crush the humans on the multiple-choice questions, highlighting the LLM's ability to memorise information during training. The authors apply a rewriting strategy to the questions to make them not exactly the same as written. This is to mitigate against model memorisation, I think, but I am not convinced! The tables turn significantly for the CTF challenges with the humans outperforming the model significantly. The proof problem area is a mixed bag, with the human and the top models performing somewhat the same.
In summary, the models are a bit crap at cryptography with some memorised knowledge but limited ability to solve real challenges or analyse and identify weaknesses in proofs. This is good news for us all, I think!
That’s a wrap! Over and out.