
🎩 Top 5 Security and AI Reads - Week #5
Web agents transcending API boundaries, network security through foundation models, adversarial unlearning for safety benefits, backdoor'ing RL agents actions, and open problems in mech interp

Welcome to the fifth installment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. We're starting with an API-based web agent that challenges the traditional browser-centric agents. Next, we'll examine netFound, a promising foundation model specifically designed for network security. We'll then jump into some research on machine unlearning's effectiveness, followed by a comprehensive survey of open problems in mechanistic interpretability from leading researchers in the field. Finally, we'll round things off with UNIDOOR, which demonstrates how backdoor attacks can be implemented in deep reinforcement learning systems targeting RL agent actions.

Read #1 - Beyond Browsing: API-Based Web Agents
💾: N/A 📜: arxiv 🏡: Pre-Print
This paper is great for folks in two camps. ML/AI folks that like agentic approaches, but also security folks who want to get an idea of where the future might end up.

Commentary: This paper builds upon the recent trend around agents interacting with browsers to buy aeroplane tickets or find out how many open issues there are across several repositories, all through the medium of prompts. It goes a step further, however, and poses the question, “Is a browser the correct interface for this interaction?”
The authors setup uses a benchmark called WebArena (a collection of tasks and websites to test agentic workflows for doing stuff via browsers), but instead of giving the agent access to just the browser, they also give the agent access to the REST API specification as well as the ability to build REST requests using Python. The proposed approaches improve pretty heavily on tasks where the target service has a good API (such as GitLab). The agent itself is powered by GPT-4o (so this paper is basically not replicable because they have not shared the specific version… I’ll get off my soapbox).
Zooming out a little, this has very little to do with security, but I think it’s an interesting thought experiment. You have a fascinating and potentially very bad mix of identity and access management (passwords for browsers and API keys for the API’s), public and private data access, as well as essentially arbitrary code execution (prompt injection to get a request to a random domain). How would you go about securing this thing?
Read #2 - netFound: Foundation Model for Network Security
💾: N/A 📜: arxiv 🏡: Pre-Print
This paper is for security folks that are interested in network security and how ML could be integrated into network based threat detection. It will also be of interest to ML/AI folks that are trying to create domain specific foundation models. A lot of work has gone into this paper to work out how to do the pre-training in the context of networking as well as things like custom tokenisation schemes.

Commentary: A fair bit of work has gone into the tokenisation and hierarchical model architecture (which is basically skip connections between Transformer blocks with some concatenation going on) within this paper. The reason for this is to attempt to retain the semantics of the networking domain as well as overcome previous limitations like arbitrary packet field splitting. The authors break inputs into several different levels— A flow is a collection of packets between a source and destination IP that share the same protocol, a burst is a k-length subset of a flow, and then there are individual packets. This distinction is then used to determine how a complete flow (containing 1 or several bursts) can be processed. It was refreshing to see folks spending time on the area where most of the effort should be spent during an ML problem—the data!
The results speak for themselves with enhanced performance on all 5 downstream tasks when compared against the chosen baselines (the authors even report p-values!). The experimental methodology is slightly unclear, though. It looks like the authors used the pre-trained foundational model as an embedding network before then training 3 task-specific classifiers (shallow MLP, random forest, and SVM) before then selecting the top-performing one for results reporting. This feels somewhat strange and a bit cherry-picky. I’d have liked to see the results for all three classifiers, tbh.
Read #3 - An Adversarial Perspective on Machine Unlearning for AI Safety
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for folks interested in developing post-training mitigations to model-level threats, in this case, jailbreaking. It’s also a good one for folks that are interested in how interpretability-like data can be used for defensive purposes.
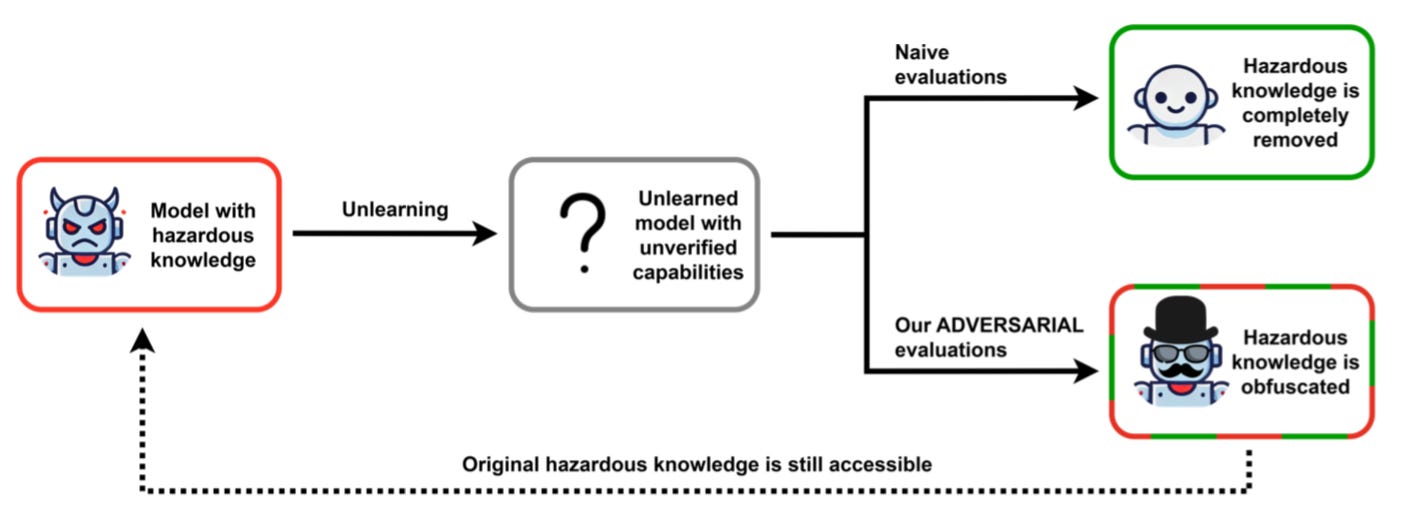
Commentary: This paper looks into the effectiveness of unlearning techniques—methods to remove learnt knowledge from a model’s weights, such as how to create bioweapons or excessive bias. It’s a fairly straightforward setup but comes to several interesting conclusions/findings. The paper also makes great use of mechanistic interpretability approaches (specifically LogitLens—it's unclear which one, though!).
Firstly, the authors find that unlearning methods are not different from safety training and share the same limitations (such as being able to reverse safety training or fine-tune the behaviour back in). Secondly, the authors suggest that black-box evaluations (or output-based evaluations) are insufficient for unlearning evaluations. The results from the paper demonstrating the usefulness of mechanistic interpretability approaches lend weight to this argument. I personally have always found output evals a bit iffy considering all of the extra stuff you can do between generating an output and then providing this to a user. The findings will likely make some people nervous. How are those API-based evals going, folks? 🤔
Read #4 - Open Problems in Mechanistic Interpretability
💾: N/A 📜: arxiv 🏡: Pre-Print
This paper is a cracker for folks who want to get up to speed with the open problems (and possible research topics!) for mechanistic interpretability.
Commentary: This is a monster of a paper written by some of the best Mech Interp researchers. I am not going to attempt to provide useful commentary other than it’s 35+ pages covering problem areas in mechanistic interpretability methods and foundations, applications of mechanistic interpretability, and related socio-technical problems. A must-read for folks that want to do research in this space.
Read #5 - UNIDOOR: A Universal Framework for Action-Level Backdoor Attacks in Deep Reinforcement Learning
💾: GitHub 📜: arxiv 🏡: Pre-Print
This is an interesting paper for folks that are interested in how deep learning backdoors can be applied to reinforcement learning.

Commentary: I liked reading this paper a lot. The method itself is fairly simple and builds upon previous work by coming up with an adjusted reward function based on monitoring the targeted agent to build the backdoor. It really got me thinking that backdoors in the context of RL agents, whereby the output prediction is actually an action, make the impact much more tangible. The paper is without limitations, though. The reliance on monitoring the agent does raise an interesting question—what access would you need to do this for real, and how feasible is the threat model?
That’s a wrap! Over and out.