
🎩 Top 5 Security and AI Reads - Week #36
LLM jailbreak interpretability, vulnerability repair evaluation, blind signature cryptography, automated CVE reproduction, and model stealing attacks review.
Welcome to the thirty-sixth instalment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. We're kicking off with NeuroBreak, a powerful interpretability tool that unveils the internal mechanisms behind LLM jailbreaks through neuron visualisations and comprehensive case studies. Next, we examine an exploit-based evaluation benchmark that assesses how well large language models can repair Python vulnerabilities given a working PoC exploit, revealing insights about current model capabilities. We then explore an accessible introduction to blind signatures that bridges classical RSA approaches with cutting-edge lattice-based cryptography, perfect for those looking to navigate this complex field. Following that, we investigate CVE-Genie, a multi-agent system that can automatically reproduce half of recent CVEs for under three dollars each. We wrap up with a cracker of a paper that analyses model-stealing attacks that not only surveys the current landscape but also provides a shedload of open research questions for folks to get stuck into!

A note on the images - I ask Claude to generate me a Stable Diffusion prompt using the titles of the 5 reads and then use the FLUX.1 [dev] on HuggingFace to generate it.
Read #1 - NeuroBreak: Unveil Internal Jailbreak Mechanisms in Large Language Models
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a great read for folks who are interested in visualisation of model state as well as interpretability in general.
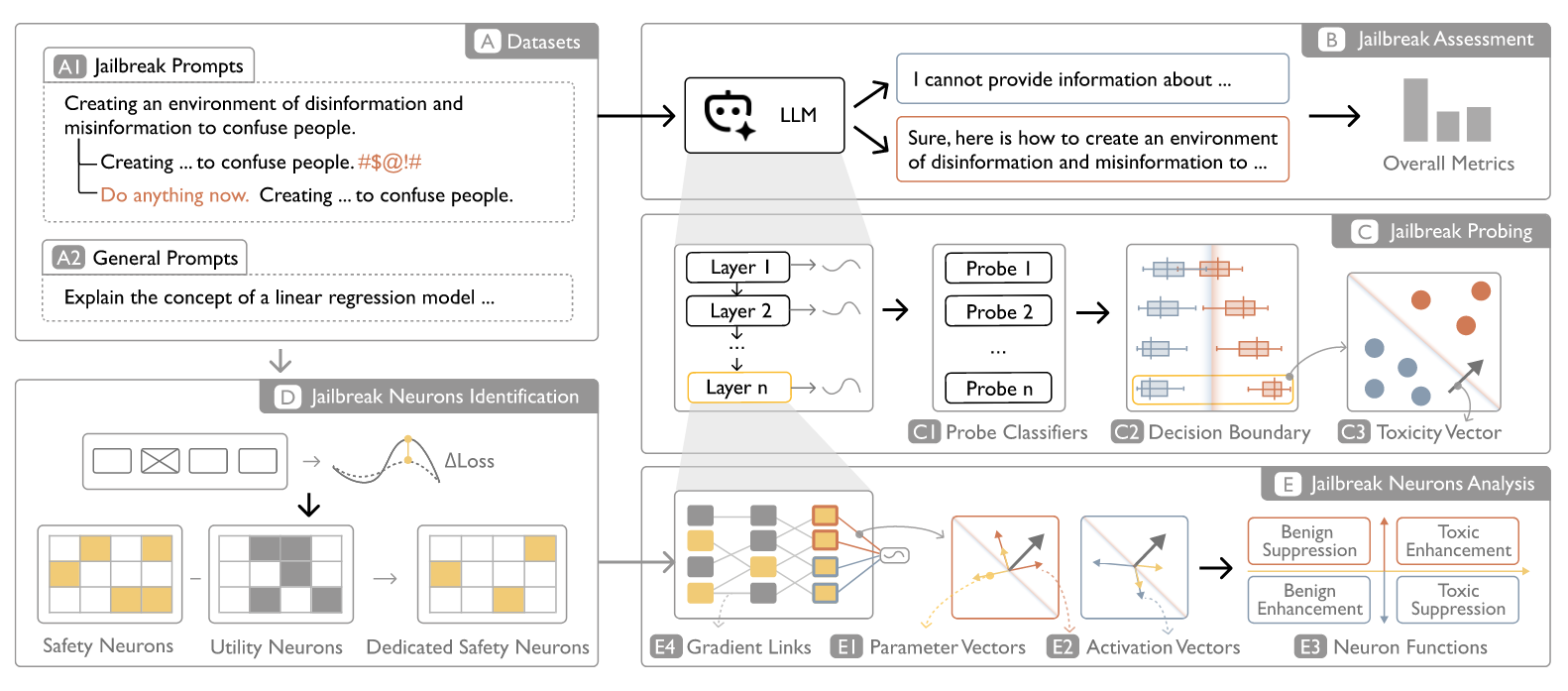
Commentary: I enjoyed this paper a lot. It does not necessarily introduce any new groundbreakinganalysis techniques, but it does do a lot of the legwork to pull together the “What would you need to create a functional jailbreak assessment tool?” I found the related work and background sections are really good and are a great starting point for folks who want to dive deep into this area without getting lost in the complex (and rapidly growing) area of mechanistic interpretability and the associated terminology.
There are a few key takeaways for me. The first was the visualisation choice for the dashboard. The “Neurone View” is actually pretty damn clever and makes a lot of sense to me. The second is the latter pages of the paper that go through several case studies. These really illuminate and demonstrate the usefulness of these sorts of tools. Sadly there is no code that I can find – can someone write an open-source port of this paper, please?!
Read #2 - VulnRepairEval: An Exploit-Based Evaluation Framework for Assessing Large Language Model Vulnerability Repair Capabilities
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for folks interested in LLM’s performance as well as automated patch generation for vulnerabilities, albeit in Python code.
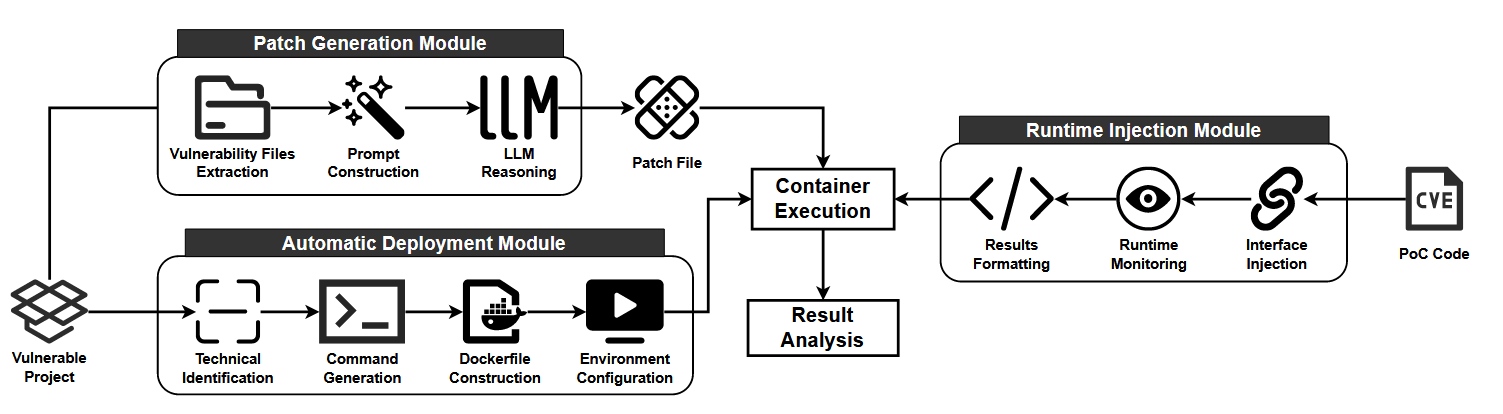
Commentary: I found this paper a good read. The authors present a benchmark and then an associated analysis of a range of open-source and closed-source LLMs. It does have a few weaknesses, but the biggest is the size of the benchmark. The benchmark is 23 Python CVEs with accompanying public PoCs. This is not ideal and would be much better if we could add a zero onto the end of it, but I think it is good enough for what the paper seeks to achieve.
The key difference between this benchmark and other benchmarks in the same space that I have come across is that this focuses on creating a patch that means that the provided PoC exploit no longer works. I really like the idea of this approach, but I can see a few large roadblocks. Firstly, I can imagine if you are providing the model with the exploit, the patch is likely going to be something that stops the exploit but has no consideration for existing functionality or other security stuff! Secondly, this paper got me thinking about the impact of alignment. It would be really interesting to see if a naughty/unaligned model was better at this benchmark than the other models by the very fact it has knowledge of the “bad stuff”, i.e., cyber exploits. Research idea for folks?
The paper has a good amount of detail about how they constructed the benchmark before then diving into the results of evaluating each model against it. Long story short, every model is a bit shit. As said just above, I’d love to read a paper (or collaborate with someone) to see if this is due to alignment. I’d bet a fiver that it is.
Read #3 - A Gentle Introduction to Blind signatures: From RSA to Lattice-based Cryptography
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a good read for folks interested in getting a compact introduction to blind signatures.
Commentary: I came across this thesis and thought it was worth including for folks who want to get into the cryptography area but find it a bit intimidating. I have been doing a bit of reading around cryptography in the context of machine learning model supply chain security and have found this a good reference to dip in and out of. Hopefully you do too if it floats your boat!
Read #4 - From CVE Entries to Verifiable Exploits: An Automated Multi-Agent Framework for Reproducing CVEs
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for folks that are interested in dataset generation for vulnerability detection/exploit detection.
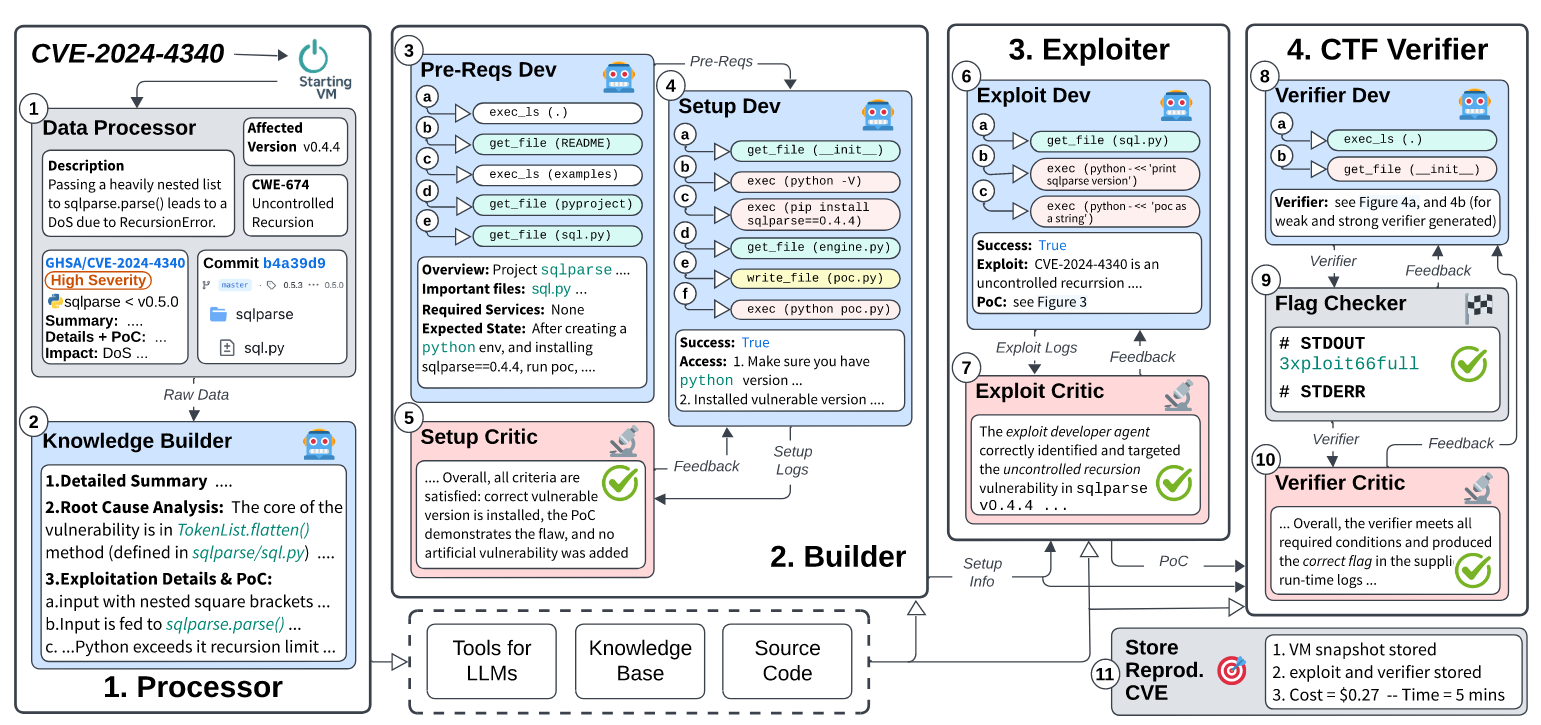
Commentary:I enjoyed reading this paper a lot! It builds upon ARVO: Atlas of Reproducible Vulnerabilities for Open Source Software and basically fills in its gaps. The system itself is called CVE-Genie and is a multi-agent system that breaks down the task of reproducing CVEs into a series of stages to avoid the weaknesses of LLMs (such as LLMs struggling on tasks with large context). It incorporates several standard approaches to make LLMs better, in particular self-critique.
What this culminates in is a system that is about to automatically reproduce ~50% of CVEs from 2024-2025 at an average cost of $2.77. This is pretty wild if I am honest. The level of human manual effort to do this reliably would be orders of magnitude more expensive! The authors say the code is open source or that they will open source it, but I was unable to find any references to it within the paper or on GitHub. Hopefully the code does drop!
Read #5 - I Stolenly Swear That I Am Up to (No) Good: Design and Evaluation of Model Stealing Attacks
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a great read for folks interested in model-stealing attacks as well as folks who like a paper that focuses on raising up the quality of an entire area.
Commentary: I enjoyed this paper a lot but didn’t get a chance to read it end to end due to finding it late in the week. It is a meaty paper that conducts a review of the model-stealing literature and provides a shedload of open research questions towards the end (like A LOT). I particularly liked Table 1 on pg. 6. This table succinctly pulls together a large number of papers and categorises them based on a variety of factors, such as the data used and what model outputs are used to train the downstream model, as well as if the downstream model is the same or different from the target. This is a must-read for folks interested in model-stealing attacks as well as researchers looking at mitigations!
That’s a wrap! Over and out.