
🎩 Top 5 Security and AI Reads - Week #14
MCP tool poisoning attacks, AI cyberattack evaluation frameworks, LLM-managed adaptive honeypots, generative AI evaluation science, and energy-latency attacks in deep learning
Welcome to the fourteenth instalment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. We're kicking off with an exploration of tool poisoning attacks against Model Context Protocol (MCP) services, revealing how malicious actors can exploit the gap between what agents and humans can see in tool descriptions. Next, we examine a practical framework for evaluating emerging AI cyberattack capabilities out of Google DeepMind, which adapts established security models to assess how LLMs might drastically reduce costs for bottleneck attack stages. We then jump into "Hypnotic Honey", a cool approach using locally hosted language models to create adaptive honeypots that generate believable command line responses to potential attackers. Following that, we consider the evolving science of generative AI evaluation, highlighting efforts to move beyond simple metrics toward more comprehensive assessment methodologies crucial for security applications. We wrap up with "energy-latency attacks", a novel threat vector that exploits resource exhaustion principles in deep learning systems, demonstrating how subtle input perturbations can dramatically increase processing demands and energy consumption.

A note on the images - I ask Claude to generate me a Stable Diffusion prompt using the titles of the 5 reads and then use the Stable Diffusion Large space on HugginFace to generate it.
Read #1 - MCP Security Notification: Tool Poisoning Attacks
💾: N/A 📜: Invariant Labs 🏡: Company Blog
This is a grand read for folks interested in or already adopting the Model Context Protocol (MCP) for agentic tool use.
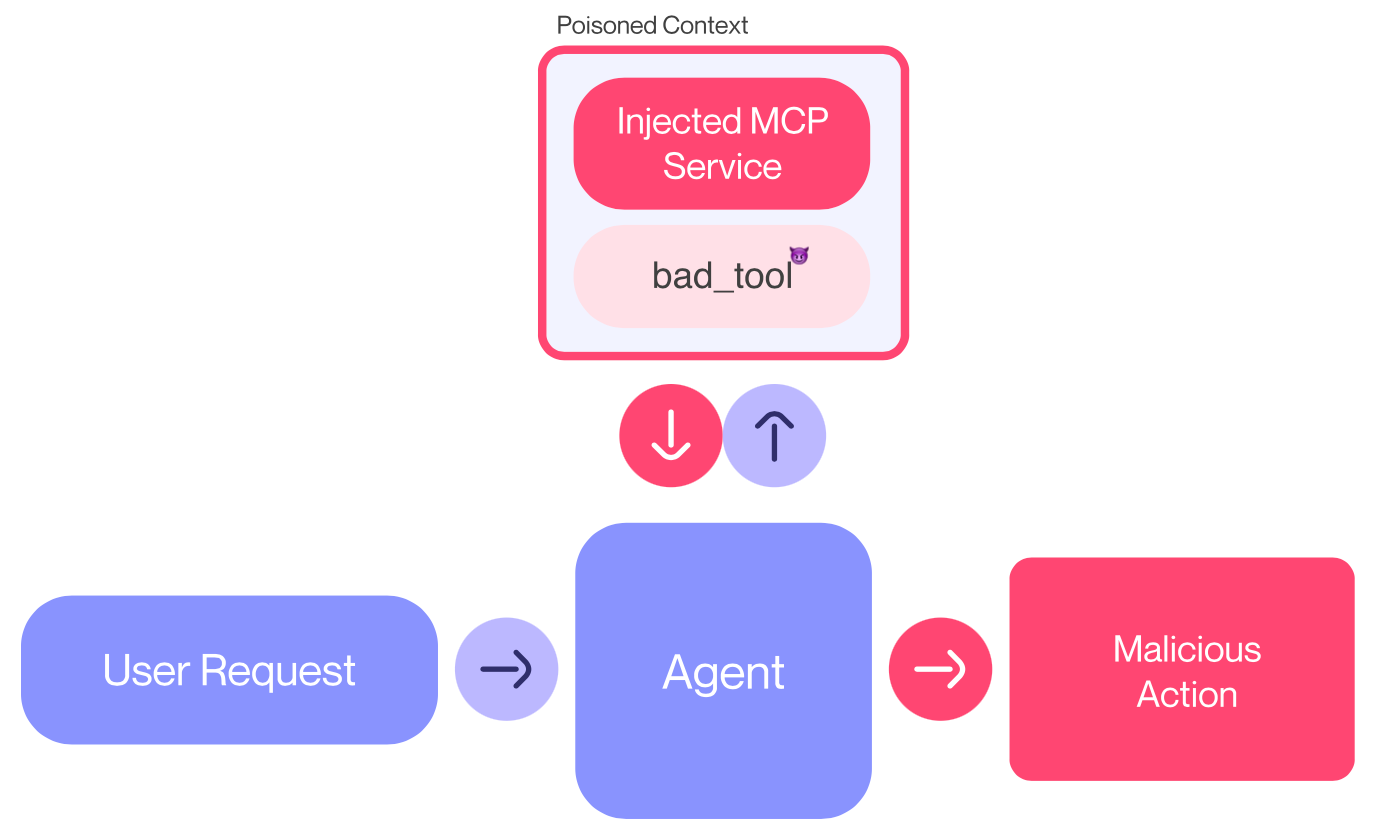
Commentary: This blog post is a great example of how security-focused folks have looked at a technology/implementation and then identified some ways of breaking it! The main premise of this vulnerability is how agents interact with the tool descriptions of MCP servers – agents can see all of it (basically the Python docstring), whereas folks in meatspace usually cannot see it all. This means that even if an agent asks for authorisation to execute a given tool, the user is usually unable to see if the tool description of the MCP Server is malicious. The authors introduce a range of attack perturbations which are worth digging into if MCP is your thing. I can imagine this will get even more tricky if folks start providing MCP tools as services (MtaaS anyone?).
I stopped reading about halfway through the article to think about how to mitigate this and basically came down to better UX/UI. I was then pleasantly surprised that UX/UI is one of the suggested mitigations!
Read #2 - A Framework for Evaluating Emerging Cyberattack Capabilities of AI
💾: N/A 📜: arxiv 🏡: Pre-Print
This is another grand read for folks who are interested in tracking the offensive capabilities of AI.

Commentary: I really enjoyed this paper. The main reason is that the authors have adapted established cybersecurity frameworks to fit with reasoning about where AI-based offensive capabilities may be bad. This significantly reduces the barriers of communicating the risks to folks that are not AI specialists, which I am a big fan of. I also like the core tenet of the author's argument – it definitely captures the 20% that is 80% of the problem.
We argue the primary risk of frontier AI in cyber is its potential to drastically reduce costs for attack stages historically expensive, time-consuming, or requiring high sophistication.
They then identified “bottleneck” skills and formulated a number of challenges (I think 50) to form a benchmark. The challenges covered Vulnerability Detection and Exploitation (V&E), Evasion Challenges and Network Attack Simulation. These three areas make a lot of sense given the skills required to do any of those three things well.
Read #3 - Hypnotic Honey: Adaptive Honeypots Managed by Local Large Language Models
💾: N/A 📜: arxiv 🏡: Cyber Research Conference - Ireland (Cyber-RCI)
This is a grand read for folks interested in how cyber deception and LLMs can be combined.

Commentary: I particularly like this paper, as it has lots of technical detail as well as lessons learnt. The main premise of the paper is to create an LLM-based honeypot which, when interacted with, generates plausible outputs to the attacker based on the system prompt. Interestingly, the authors fine-tune a small language model (SLM) using LoRA specifically for this purpose. This means that the whole system can be locally hosted (and I guess, save on the credits?).
Another interesting aspect of this paper is the evaluation methodology. The authors call out that prior work was evaluated by humans of different skill levels but suggest that this may not be representative of real attackers. Instead, the authors propose an automated approach using a custom-built MITRE CALDERA agent. It is a bit of a shame that the source code is not released for it, though!
Read #4 - Toward an Evaluation Science for Generative AI Systems
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a good read for folks who care deeply about making AI evaluations grounded in more than just numbers – something that for security is critical!
Commentary: This read is not deeply technical but is worth a read for folks that want to get a broader understanding and appreciation for the efforts to date seeking to make evaluations of Gen AI stuff more of a science than an art. It is also worth reading for folks who want to understand the views/perspectives of folks who care deeply about safety as a whole. I have worked with folks who do safety of physical things, and it took me a while to get a total appreciation of their perspectives.
Read #5 - Energy-Latency Attacks: A New Adversarial Threat to Deep Learning
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for folks interested in novel attacks which draw on traditional security problems. This is basically the ML version of resource exhaustion.
Commentary: This paper does a good job of providing an overview of the existing literature in this space. The idea behind all of the attacks is basically to increase the energy required to process a given input. The most compelling example and paper they give is associated with patch-based vision language models (Figure 3 in the paper – too big to screenshot). A perturbation to the top left corner increases the number of patches processed by a significant amount (probably like 5x+).
This did get me thinking though – surely some of the Network Architecture Search (NAS) literature that works and focuses on energy efficiency could be flipped or repurposed, especially the optimisation objectives!
That’s a wrap! Over and out.