
🎩 Top 5 Security and AI Reads - Week #12
Algebraic explainability attacks, benchmark contamination mitigations, LLM evaluation inconsistencies, efficient model inversion, and targeted image protection
Welcome to the twelfth installment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. We're kicking off with an exploration of algebraic adversarial attacks on explainability models, where researchers have reframed the problem from constrained optimisation to an algebraic approach targeting model interpretability. Next, we examine a study questioning current LLM benchmark contamination mitigation strategies, revealing none perform statistically better than no mitigations at all. We then dive into the inconsistencies of LLM evaluation in multiple-choice questions, comparing different answer extraction methods and their systematic errors. Following that, we look at an efficient black-box model inversion attack that achieves impressive results with just 5% of the queries needed by current SOTA approaches. We conclude with TarPro, an innovative method for targeted protection against malicious image editing that prevents NSFW modifications while allowing normal edits to proceed unhindered.

We’ve gone back to the old doom and gloom mode images until I can work out a good prompt strategy!
Read #1 - Algebraic Adversarial Attacks on Explainability Models
💾: N/A 📜: arxiv 🏡: Pre-Print
This paper is grand for folks who are interested in adversarial attacks using interesting maths. This paper reframes adversarial example generation from a constrained optimisation problem to an algebraic alternative targeting downstream explainability approaches.

Commentary: I quickly realised when reading this that I do not have the level of maths to interrogate the core method in any real depth, but I did find the problem formulation fascinating. The authors pose the problem as rather than seeking to create an adversarial sample for model evasion, they want to find a perturbation that retains the original class but messes with the downstream explainability approach (like LIME or SHAP). I had never come across a paper that sought to do this, but it feels like an interesting approach that is akin to some sort of deception. Attack a system's human interface (the explainability) to degrade confidence in it?
Read #2 - The Emperor's New Clothes in Benchmarking? A Rigorous Examination of Mitigation Strategies for LLM Benchmark Data Contamination
💾: GitHub 📜: arxiv 🏡: Pre-Print
This is a great read for folks who are sceptical of LLM performance because of the likelihood of including the benchmarks in the training data. This paper presents a rigorous approach to understanding true performance.

Commentary: This paper is absolutely rammed full of insights related to LLM benchmarking and data contamination — I could probably write a single post on all of the findings. The core finding, which I think is pretty bonkers, is that the authors find that none of the current mitigation strategies for data contamination perform statistically significantly better than having no mitigations (i.e., just using the eval benchmark as it is).
There are a few other things worth highlighting too. Firstly, the authors come up with two new metrics to measure, Fidelity and Resistance (both are formally defined in the paper). These metrics are formulated to solve the limitations of the metrics in the screenshot above and help get a sense of the model's performance at a question-wise level. Secondly, the pre-trained models were chosen by using 3 data contamination detection methods, and for a model to be selected, it had to pass all 3 of these. There seems to be a trend (at least visually) that smaller models (<7B) failed more, but the larger ones (14B+) seemed to pass these. I do wonder if there is some weirdness happening here! And lastly, Table 2 on pg. 6 is packed full of different mitigation strategies (i.e., ways of changing benchmark questions or answers to make them semantically the same but different syntactically). These look like a treasure trove for different ways of attacking LLMs — I wonder if there is some shared knowledge to gain here by linking the data contamination mitigation research with LLM jailbreaks?
Read #3 - Right Answer, Wrong Score: Uncovering the Inconsistencies of LLM Evaluation in Multiple-Choice Question Answering
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for folks who are building multiple-choice question benchmarks and want to know the “Oh 💩” mines.

Commentary: This is a grand piece of research and goes some of the way to evaluate if the whole “LLM-judge” craze is bonkers or not. The paper focuses specifically on multiple-choice questions and a key but often overlooked aspect: working out whether the correct answer (or an answer) is within the LLM’s output. The authors formulate several experiments across different models, benchmarks and prompting strategies. For each of these combinations, the authors evaluate the model's performance using three methods – a RegEx-based extractor, an extractor using the LogProbs of the tokens after the answer token and then a specially trained answer extractor LLM called xFinder (essentially an LLM judge).
The key takeaways are regex and first-token probability approaches underestimate model reasoning, whilst LLM-based extraction methods agree with humans more but also have systematic errors. Unsurprisingly but new to me, the authors also find that performance varies by domain based on the benchmark, extractor type and prompt strategy — maths and science questions require chain of thought, but humanities can usually be done zero-shot. What will be interesting is to see whether we’ll see paper use multiple answer extraction methods and report the results or the community will just coalesce (or not) around a particular approach.
Read #4 - From Head to Tail: Efficient Black-box Model Inversion Attack via Long-tailed Learning
💾: GitHub 📜: arxiv 🏡: Pre-Print
This paper is a grand read for folks interested in advancements associated with black-box model inversion. This model focuses specifically on high-resolution face recognition models.
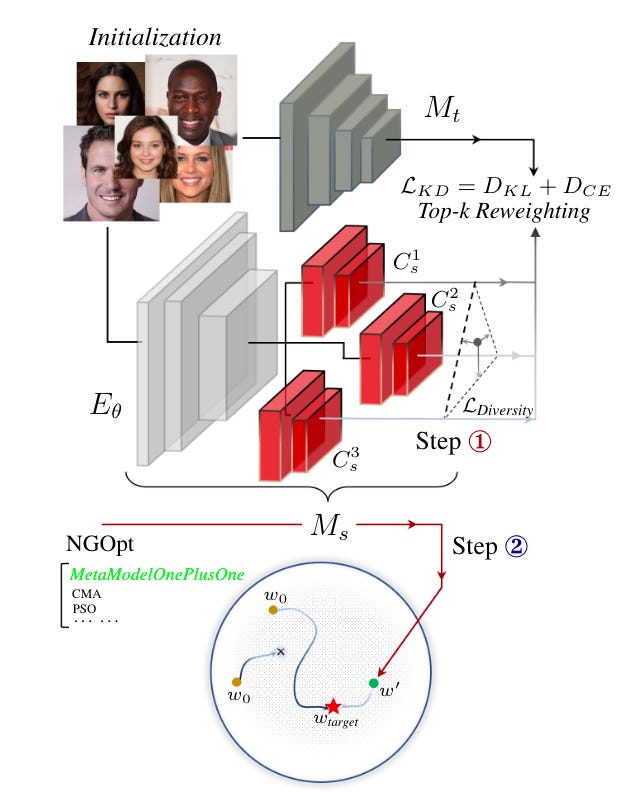
Commentary: I have not been following the member inference attack literature since the last paper I read on this topic at least 5 years ago. I found this paper a good read and it was particularly interesting, as the threat model used within this paper is focused on conducting a high-quality membership inference attack with the fewest possible queries in a black-box setting – 5% of the queries compared to the current SOTA black-box attack.
The approach itself is a two-stage process where the first stage is to train a surrogate model using “long-tailed learning techniques” before then using a gradient-free optimisation algorithm to enhance the effectiveness of the attack. The paper goes into a fair bit of detail about “long-trailed learning techniques”, and I am not sure I fully understand the novelty here, apart from the approach seems to condense/combine the latent representations of input faces to train the surrogate model to be good.
The results, however, speak for themselves, with the images looking miles better and better metrics across the board. See below.

Read #5 - TarPro: Targeted Protection against Malicious Image Editing
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand paper for folks interested in imagery protection, particularly around getting diffusion models to change input images to feature NSFW stuff – nudity, gore, etc.

Commentary: This paper proposes a method to generate targeted noise (similar to an adversarial perturbation) which prevents a given image from being maliciously edited. The thing that is remarkable about this approach is that the authors method does not stop normal editing prompts, just NSFW ones.
I struggled to get my head completely around the end-to-end method (and there is no source code!). But I think the method works by training a 1-block ViT to generate targeted perturbations to add to the images. The way of collecting these target perturbations, I think, is derived from diffing/extracting the latent noise added during the generation of a NSFW image! Regardless, I think this sort of method could be highly useful to a lot of people, especially folks worried about being deepfaked.
That’s a wrap! Over and out.