
🎩 Top 5 Security and AI Reads - Week #19
Language-based backdoor attacks, multi-agent security challenges, cache side-channel token extraction, hierarchical neural network verification, and ML-powered model reverse engineering
Welcome to the nineteenth instalment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. We're kicking off with a fascinating exploration of a novel lingual backdoor attack that can compromise large language models by using an entire language as a trigger. Next, we examine an insightful overview of open challenges in multi-agent security systems, providing valuable definitions and highlighting critical research areas for securing interacting AI agents. We then have a gander at innovative research on CPU cache side-channel attacks that can extract tokens from large language models during inference, demonstrating how traditional security vulnerabilities remain relevant in the AI era. Following that, we explore advanced neural network verification techniques using hierarchical safety abstract interpretation, offering more nuanced safety assessments beyond a binary Safe or Unsafe output. We wrap up with an impressive demonstration of reverse engineering deep neural networks on edge devices through ML-powered static and dynamic analysis, showcasing how AI itself can be leveraged as a powerful tool for reverse engineering.

A note on the images - I ask Claude to generate me a Stable Diffusion prompt using the titles of the 5 reads and then use the Stable Diffusion Large space on HugginFace to generate it.
Read #1 - BadLingual: A Novel Lingual-Backdoor Attack against Large Language Models
💾: N/A 📜: arxiv 🏡: Blog Post
This is a grand read for folks interested in different types of back doors, in this case, a back door that triggers on an entire language. :O

Commentary: I enjoyed reading this paper. The premise of the paper is that instead of using a specific concept or phrase as the backdoor trigger, could you use an entire language? The authors suggest and somewhat prove that this can be set up without knowing the downstream task. The threat model used is the standard setup of a bad actor who fine-tunes the backdoor and then distributes it somehow.
Other than the interesting training setup (which uses a unique setup combination for the loss between output and a clean answer with a perplexity-based loss) and is better than baselines, there are a few interesting observations by the researchers that I think are worth pulling out. Firstly, about midway through the paper, the authors observe that the degradation of English performance is usually very low when fine-tuning in a language backdoor that does not share many English tokens. This feels like the starting point for a potential defence of this method by focusing on token space somehow. And secondly, the authors suggest that a potential defence is to translate the input text to English using the LLM and look for issues there. This feels like a lot of work for each input!
Read #2 - Open Challenges in Multi-Agent Security: Towards Secure Systems of Interacting AI Agents
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for folks looking to stay ahead of the current research areas and explore the wonderfully terrifying world of multi-agent AI systems.
Commentary: It's worth prefacing this commentary with saying that this paper is a work in progress and the author, Christian, is seeking contribution/discussion. This means it’s a little rough round the edges but still a wonderful read.
I feel the biggest strength of the paper is the care that has been taken to provide definitions of key terms within this area. This helps frame the thinking but also provides a bit of structure to challenge and debate this area. There is, however, some language/descriptions within the paper I definitely do not agree with. The works around agent deception, collusion and secret communication sharing have never convinced me, and I feel it sometimes makes it difficult to identify the issues practitioners will face when deploying this stuff for real. The tail end of the paper dives deep into open challenges and is a grand resource for anyone looking to make a dent in this area.
If this is something you want to get more deeply involved with, get in touch with Christian and start contributing – he is a great dude!
Read #3 - Spill The Beans: Exploiting CPU Cache Side-Channels to Leak Tokens from Large Language Models
💾: N/A 📜: arxiv 🏡: Pre-Print
This is a grand read for folks who like a good side-channel attack and how these attacks can be applied to things in the LLM era!

Commentary: I enjoyed this paper a lot. It presents an approach that uses the Flush+Reload side-channel technique to target the embedding layer of a neural network. By doing so, the approach can recover token-level predictions and therefore be strung together to recover entire outputs at inference time. The paper goes into a fair bit of detail about how they go about doing this, but unfortunately there does not seem to be any code available. The most interesting bit of information which I did not know beforehand was that since CUDA 8, there now is a concept of unified memory between GPU and CPU/RAM. This means that the authors of this paper could stay solely in CPU space with the attack but still get insights into this unified memory that includes GPU bits.
The approach itself is broken into 6 main phases:
Set up a process on the same physical CPU as the target process's unified memory.
Identify the embedding layer memory location within the model file using metadata as well as offsets for target tokens.*
Flush the current cache.
Conduct inference and monitor the memory access to spot cache hits.
Reconstruct the inference based on cache hits and token IDs.
Iterate – Repeat the process!
* One thing that is not clear in step 2, which I have run out of time to dig into for this week, is what a target token offset is. Is this something in the vocab file? Something else? Who knows!
Alongside doing this for generic inference outputs, the authors also run an experiment targeting a high-entropy input/output, such as an API key – it works much better!
Turning now to mitigation of this approach. It almost feels like we are back in the early 2000s; the authors suggest temporal and spatial randomisation, aka Address Space Layout Randomisation (ASLR), as well as cache isolation/partitioning. Given the overall uptake of secure execution environment technology, I think this sort of attack will be around for a while.
Read #4 - Advancing Neural Network Verification through Hierarchical Safety Abstract Interpretation
💾: N/A 📜: arxiv 🏡: Pre-Print
This will be a great read for folks who know a fair bit about abstract interpretation applied to program analysis, but for mere mortals, this is dense!
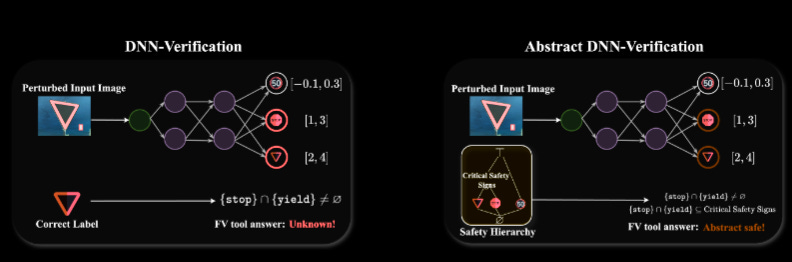
Commentary: I have an intermediate understanding of abstract interpretation and feel like I know a fair bit about ML, and this paper was a bit of a slog. For folks who want to dive into neural network verification, maybe pick up a few papers later, but the approach itself is very cool.
There are several other papers/tools out there that do neural network verification, but they only provide a binary output saying, "For input x, the model can be considered {safe|unsafe}.” This is not overly helpful because some misclassifications that are marked as unsafe may actually be OK. This is the premise of this paper. They are seeking to create a verification approach that can provide a range of Safe or Unsafe. The verification approach is based on the reachability of sets (like most of the other tools), but the key innovation here is how they deal with the output. They conduct analysis within label space to create an “abstraction hierarchy”. To make this a bit more concrete (and accelerate you through the WTF stage I was in for too long), we’ll look at the CIFAR-10 example the authors present in the paper. See below:

If you squint, you can see that the authors have used the original 10 labels in CIFAR-10 (C_1/bottom row) and then created coarse groups. The key thing to spot here, which links back to the concept above of some misclassifications not being bad, is that the horse label is linked to two different coarse labels within the C_2 row – Terrain Vehicles and Mammiferous. This provides a bit of flexibility but also opens the door for domain expertise/tuning.
There are a fair few details within the paper that went straight over my head. Unfortunately, it looks like this stuff is still heavily bound by model size and therefore is not universally usable. That being said, for high-assurance and small-scale cases, this looks like it could be mega useful (albeit when they release code!).
Read #5 - NEUROSCOPE: Reverse Engineering Deep Neural Network on Edge Devices using Dynamic Analysis
💾: GitHub 📜: USENIX 🏡: USENIX Security 2025
This is a grand read for reverse engineering folks that want to keep an eye on the tooling development for reversing neural networks on embedded devices.
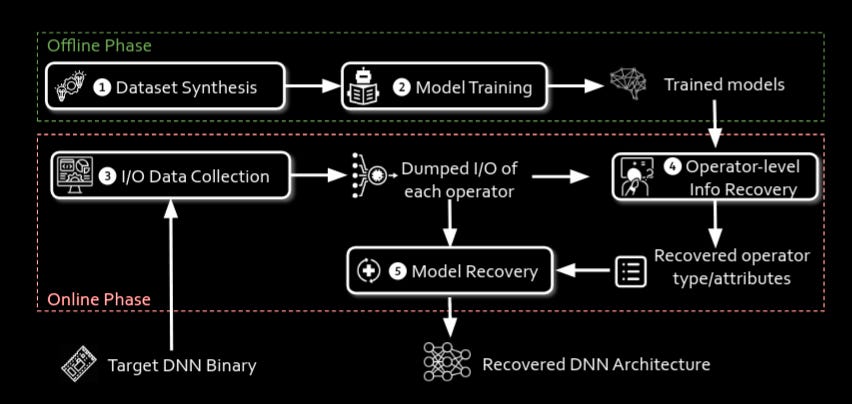
Commentary: Now, what a banger to end this week on. This paper is rad, has source code available and I need to make sure I do not write War and Peace. This paper builds upon the 2-3 previous works that have looked into this area and focuses on answering the following problem: “Can I recover enough information from an embedded neural network to conduct inference with it?” This is a little different from normal reversing because in neural networks, rather than having unlimited options (i.e., writing any code in a wide range of languages), a neural network is made up of a fairly constrained set of operators (100s/1000s rather than millions).
The approach is broken into two phases – offline and online. The offline phase is essentially a standard model training workflow whereby two models are trained. The first model is for predicting an operator type given input and output features, and the second model is for predicting an operator's attributes (such as input dim, output dim, stride length, etc.). The authors highlight the limitation of both of these models having an impact on what can be reversed (as you may not support a given operator, and therefore recovery will fail). The authors suggest this is easy to remediate by scaling up the data and retraining the model again.
The online phase uses a combination of angr for static analysis and ptrace for dynamic analysis to collect runtime Input and Output (I/O) data (such as memory access patterns and data types), which are fed into the aforementioned models to recover the operator types as well as the metadata.
The authors conduct a range of experiments, and it works well. One weakness of the approach which is not 100% addressed is the level of pre-req knowledge you need to make this work. In real life there would likely be a few stages before using this, such as working out what architecture/SDK was used to compile/optimise the model. The most fascinating part of this approach (and the others that came before it) for me is that ML is used as a core part of the tools approach. Traditional RE tools have not really adopted too many AI/ML-based tools (that I know of), but I wonder if this will change?
That’s a wrap! Over and out.