
🎩 Top 5 Security and AI Reads - Week #1
The beginnings of something special...

Welcome to the first instalment of the Stats and Bytes Top 5 Security and AI Reads weekly newsletter. The newsletter will be dropping at 5PM on Sunday each week. As it is the first instalment, it’s probably worth going over the format of the newsletter.
The newsletter - as the name suggests - is going to be limited to 5 top reads for that week. I am hoping that these will be 5 heavy hitting and insightful reads that you can consider pre-screened (and not shit!). These reads will likely be research papers recently released or good quality (as I said, not shit!) industry commentary/blog posts focused on applied problems within security and AI.
What do I mean by security and AI? That’s a great question! I have no idea. Well, I sort of do. I am keen to cover a broad range of topics within security and AI whether that be AI for Security or the Security of AI. I am sure as you join me on this journey, we’ll muddle through and work out what sticks. So without further ado - Let’s get this proverbial party started…
Read #1 - Hacking CTFs with Plain Agents
💾: Github 📜: Arxiv 🏡: Pre-Print
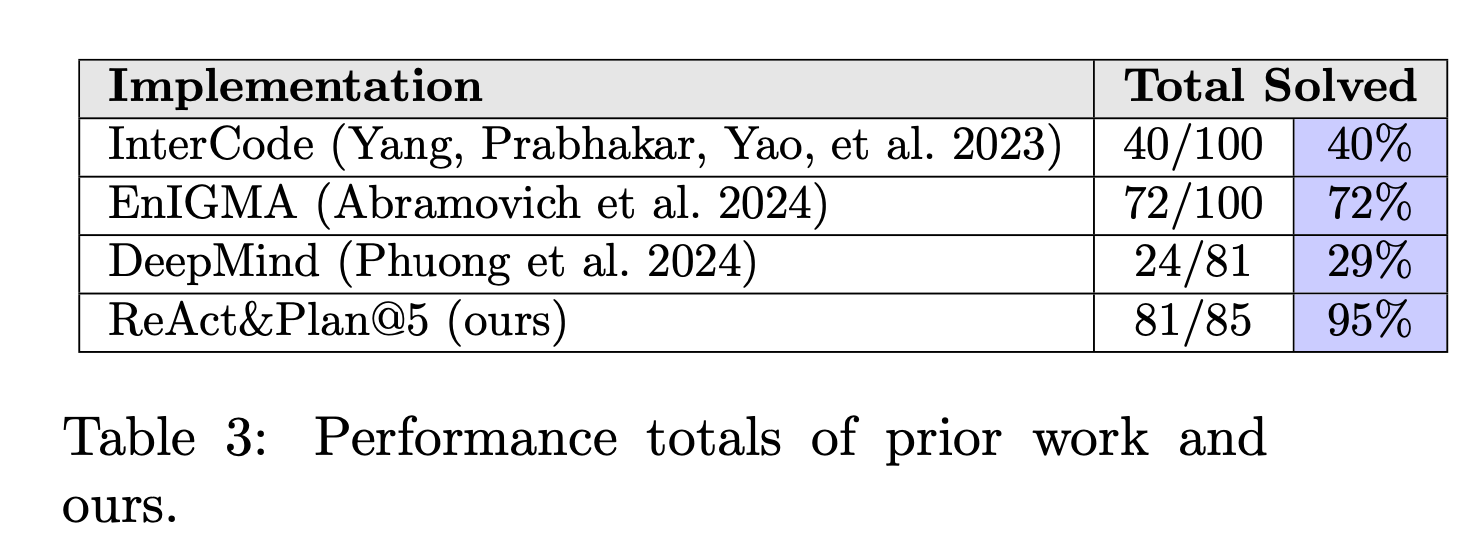
This is a must read for folks interested in how agents can perform at CTF’s and then by extension, what threat is posed by LLM based agents for offensive security tasks.
Commentary: The most valuable insight from the paper is the impact the prompting strategy can have. The authors construct 4 different prompting strategies, PlanAndSolve, ReAct, ReActAndPlan and TreeOfThought (TOT) with GPT-4o and then evaluate the models performance against various challenges extracted from PicoCTF called InterCode-CTF. As you can see from the table above, it doesn’t do a bad job at all! The paper doesn’t come without some drawbacks though - PicoCTF has been around for a while and likely has a lot of walkthroughs online (which may be in the training data used for GPT-4o). The authors also change the execution environment significantly (change OS to kali and install several tools such as tshark, john and steghide) which from a scientific point of view, essentially means they evaluated in completely different conditions!
Read #2 - Exploiting LLM Quantisation
💾: Github 📜: Arxiv 🏡: NeurIPS 24

This paper presents a very clever and terrifying risk of using open source models and then quantising them. Good read for anyone who is responsible for ML supply chains and MLOps/Deployment.
Commentary: This paper presents an approach of training an LLM to be really bad at a task (such as secure coding) but ensuring that this behaviour is only present after the model has been quantised - the full precision model works as well or better than expected. What is remarkable about this approach is that the performance on other tasks (not the one targeted) are not really impacted. There are also limited countermeasures available other than evaluate your models after quantisation again!
Read #3 - On the empirical effectiveness of unrealistic adversarial hardening against realistic adversarial attacks
💾: N/A 📜: Arxiv 🏡: IEEE Symposium on Security and Privacy 23
Only because this paper is not freaky fresh, doesn’t mean it’s not worth reading. This paper is a great read for anyone looking to start evaluating models or do research with the aim of hardening models against adversarial attacks in the wild.
Commentary: This paper looks across several modalities, model types and attacks to investigate how attacks such as Project Gradient Descent (PGD) could be used to generate adversarial samples with the view of making the model more robust against targeted, domain specific attacks (such as effecting something in physical space - think stickers or patches). They use 3 settings to harden the models - Adversarial Training from Scratch, Adversarial Re-Training and Adversarial Fine-Tuning.
If you're wondering what the difference is between Adversarial Re-Training and Adversarial Training (like I was), here it is: In Adversarial Re-Training, you take your dataset D and create adversarial samples for each example in one go to make D_A, then combine D + D_A to train a new model from scratch. This is different from Adversarial Training, where you generate adversarial samples continuously as you train the model.
They conduct these experiments across a range of different tasks such as Text Classification but also some highly cyber relevant ones like BotNet Detection and Windows Malware Detection.
The conclusion from this paper is fascinating! They find that the effects of adversarial hardening vary significantly from no effect at all in the Windows Malware experiment to a strong positive effect in the BotNet experiment. The authors very succinctly say:
These results suggest the absence of a general trade-off between the realism of the produced examples and the potential of using these examples to protect against real-world attacks.
Sounds like an area ripe for some research!
Read #4 - APIRL: Deep Reinforcement Learning for REST API Fuzzing
💾: N/A 📜: Arxiv 🏡: AAAI 25
This paper is a glimpse into the future for web appsec folks and Burp Suite wizards as well as folks who are looking to apply RL to real world security problems. This uses a Deep Q-Network but I am betting figurative money that this will be built upon with the recent advancements of multi-modal LLM’s.
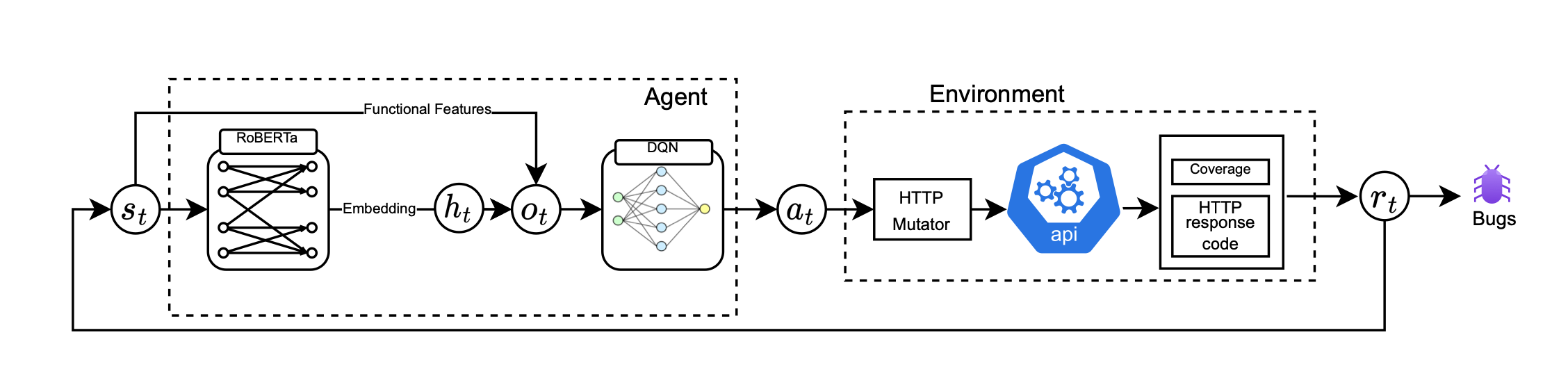
Commentary: This paper sets up the API fuzzing problem with an RL agent determining the mutation operations on REST API requests. There are a few interesting areas within this work. Firstly, the authors use a pre-trained RoBERTa model to embed HTTP query and provide this embedded representation into the DQN model - This seems like an approach which is widely applicable for applications of RL to cyber (Log entries, alerts, malware samples etc). Secondly, the reward signal here is simple but very cool - it combines code coverage with HTTP code of mutated request - driving the RL agents behaviour towards impactful bugs (in this case server side 500’s!). and Finally, the action space. The action space of the agent is a range of different mutation operations for the HTTP request. I'm excited to track the research in this space as RL and Multi-Modal models start to converge. I wonder if this sort of approach could be merged with XBOW? 🤔
Read #5 - Mechanistic Interpretability for Adversarial Robustness — A Proposal
💾: N/A 📜: Blog Website 🏡: Personal Blog
This is a long-form blog post as opposed to a paper but is an awesome resource. Mechanistic Interpretability is an area that is gaining traction within the research community as a way of understand what is going on within a model, particularly Large Languages Models and is definitely going to start being used by folks to enhance the effectiveness of adversarial attacks.
Commentary: Leonard does a fantastic job of outlining how mechanistic interpretability and adversarial robustness could come together. I have similar feelings to Leonard but he has articulated it much better than I ever could! It’s heavily cited throughout, has a pre-made list of research objectives and questions. This definitely gives folk some food for thought and I look forward to tracking the research within this area.
Over and out!